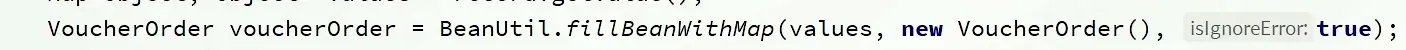redis实战篇
用户发送短信
。。。略
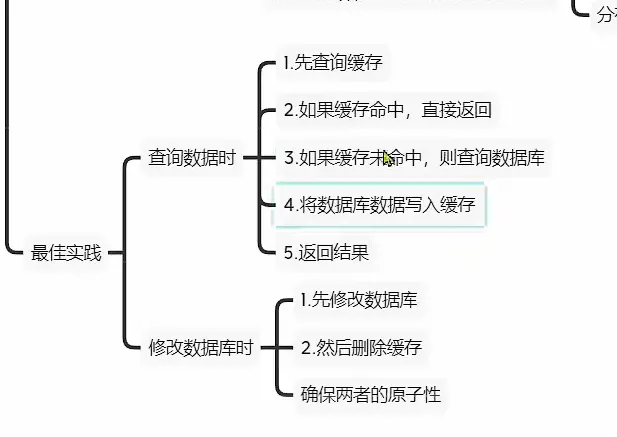
商户查询缓存
缓存更新策略

一般来说, 我们选择 方案1就好了
选择删除缓存 (懒标记)
如何保存缓存与数据库的操作
- 单体
- 分布式, 使用TCC等分布式事务方案
先删除缓存 ,在操作数据库 或者放过来
两个任务在并发操作的时候, 都会有可能
但是后面那种方法,出现出现线程安全的概率较低
实战开始
缓存穿透
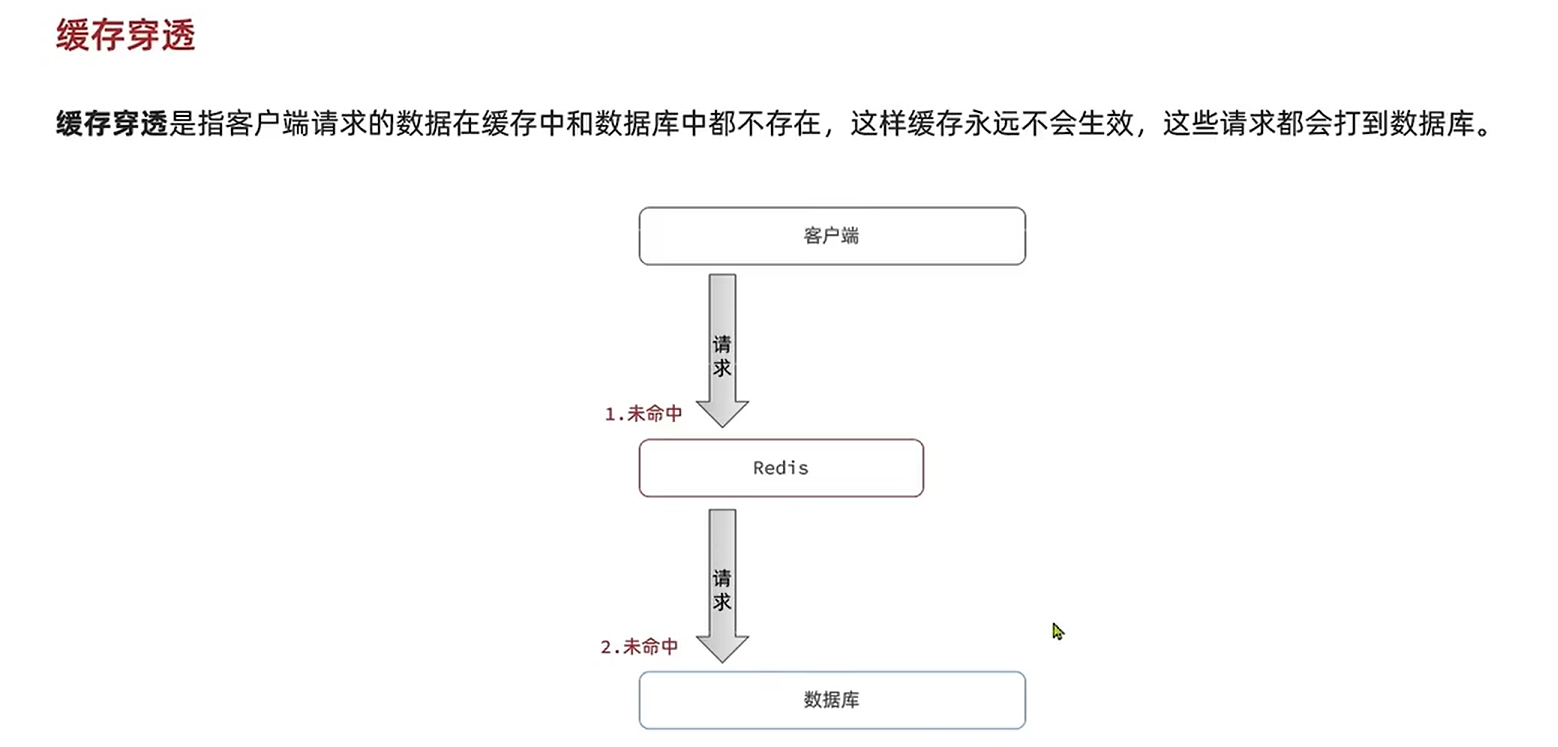
解决方案
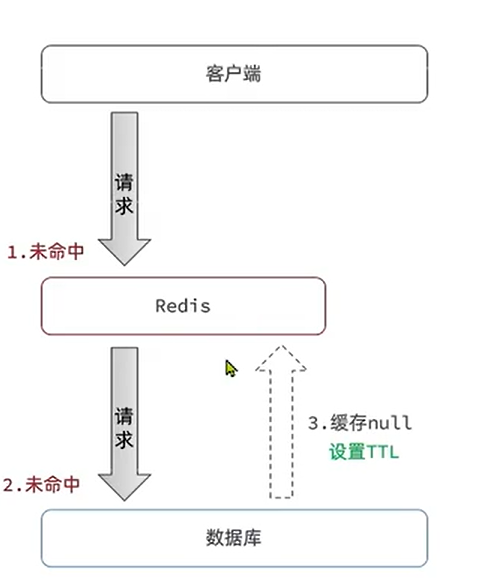
- 缓存空对象
优点:实现简单, 维护方便
缺点: 额外的内存消耗, 可能会操作短期的不一致
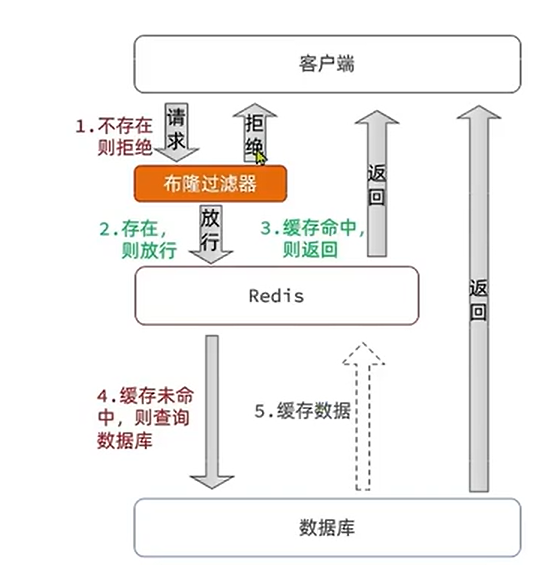
- 布隆过滤
在客户端到redis中设置一个过滤器
优点:内存占用少, 没有多余的key
缺点: 实现复杂, 存在误判可能
实战
这里我们选择方案一
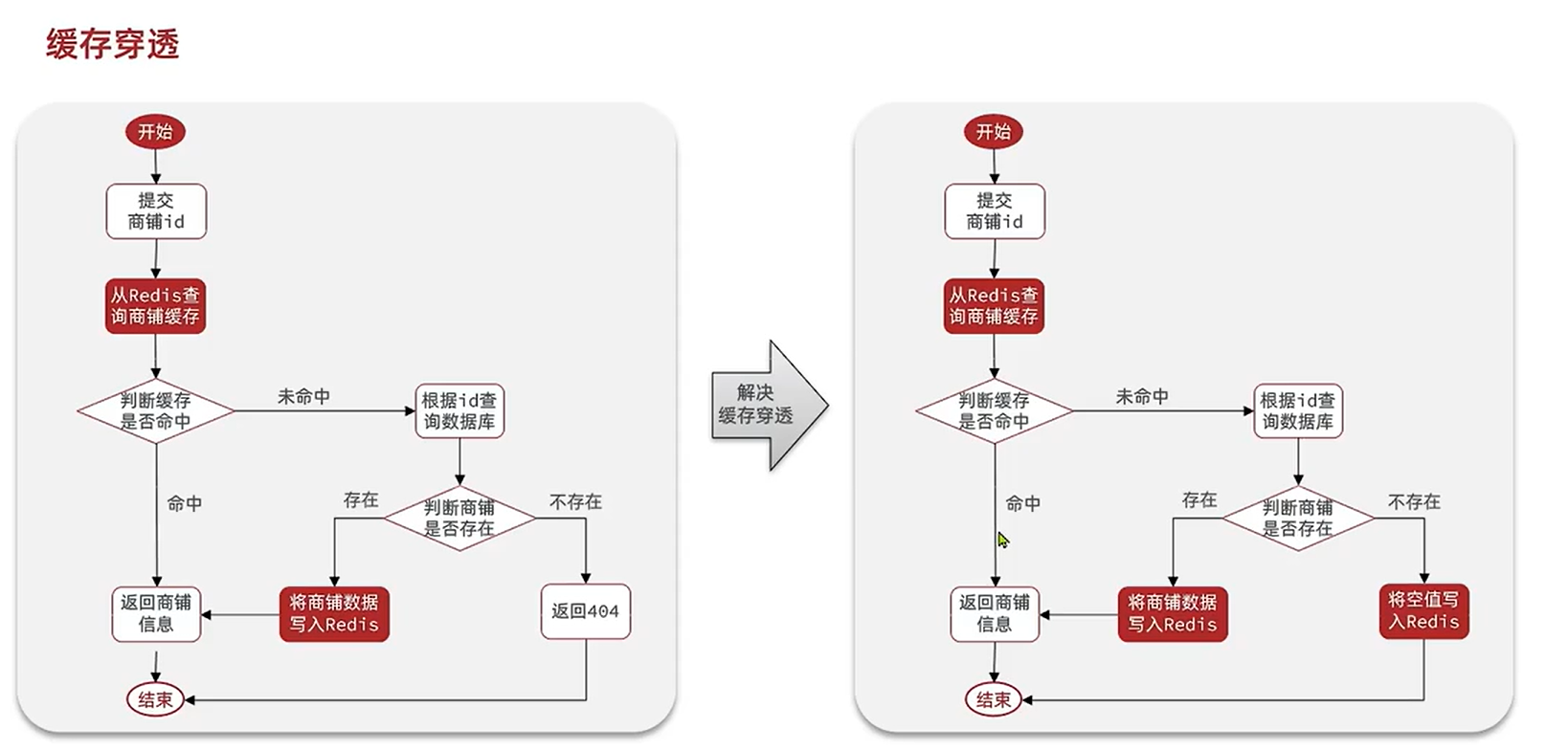
作用就是: 用户查询的数据在缓存的数据在数据库和缓存都不存在, 我们可以用方案1, 这样下次 就只用缓存, 减少数据库的压力
当然, 我们可以设置一些id的格式规范, 然后判断id的规范, 来进行判断。或者
进行用户权限的校验
来解决缓存击穿问题
缓存雪崩
- 问题
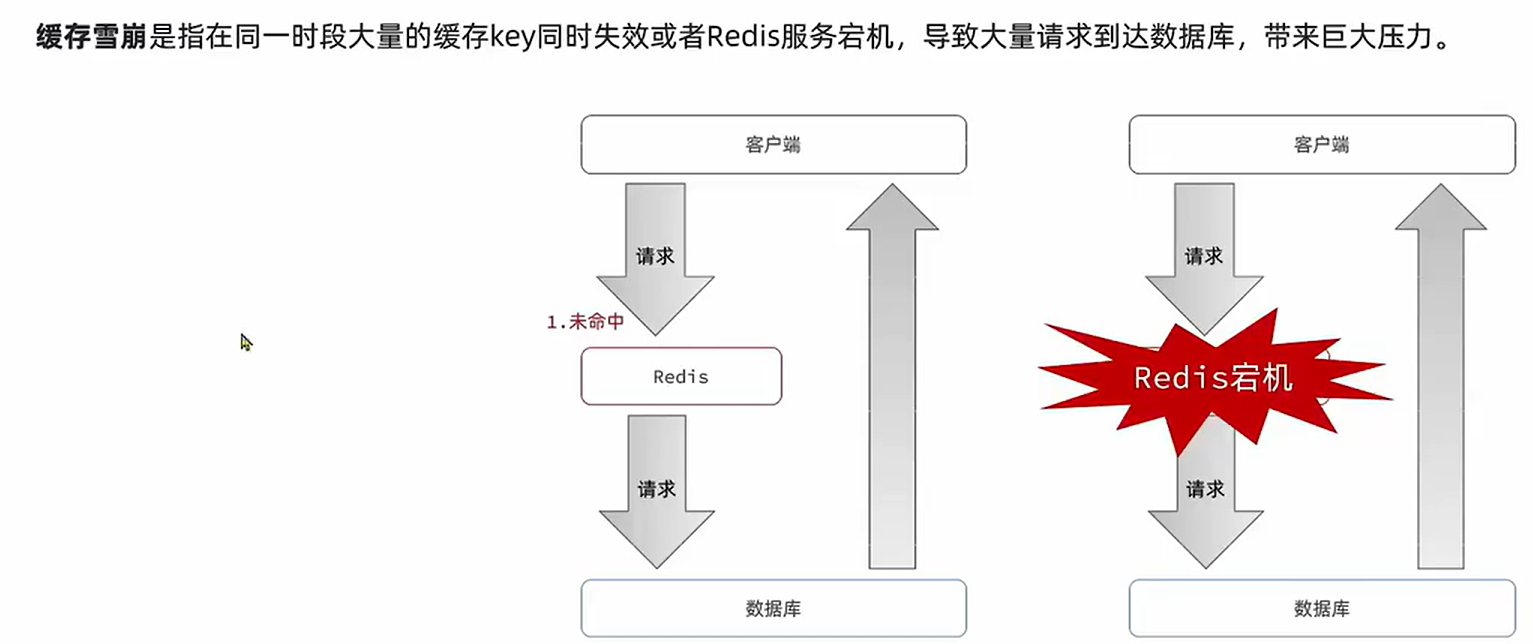
解决方案
- 给不同的TTL设置随机值
- 利用Redis集群提高服务的可用性
部署多个集群。避免这种问题
给缓存业务添加降级限流策略
拒绝服务, 保护数据库的健康
给业务添加多级缓存
nginx , jvm , 等多个缓存。
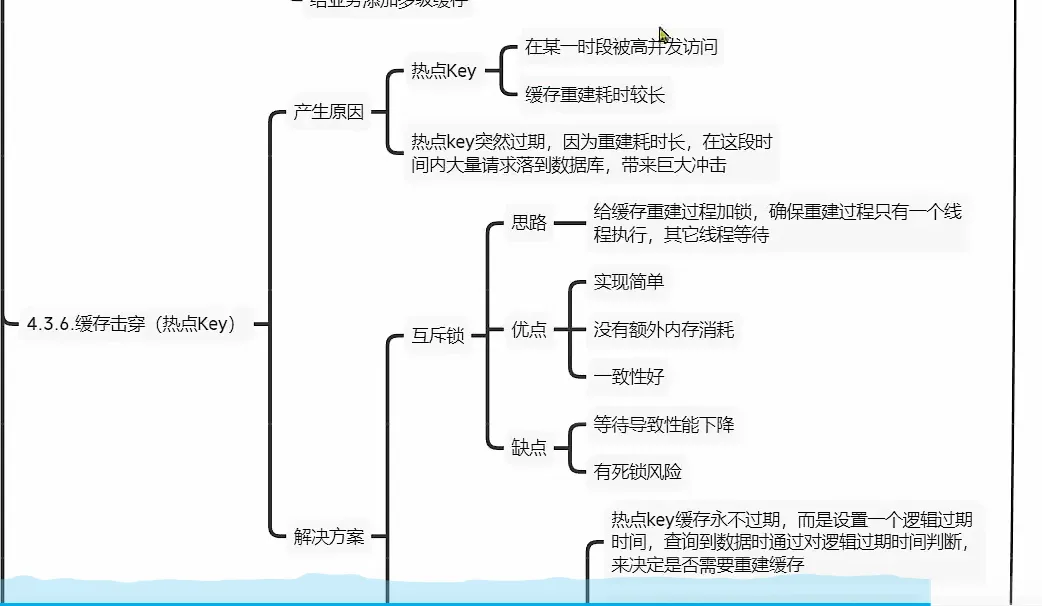
缓存击穿
- 部分key 过期, 造成的问题
一个高并发访问并且缓存重建业务较为复杂的key失效了
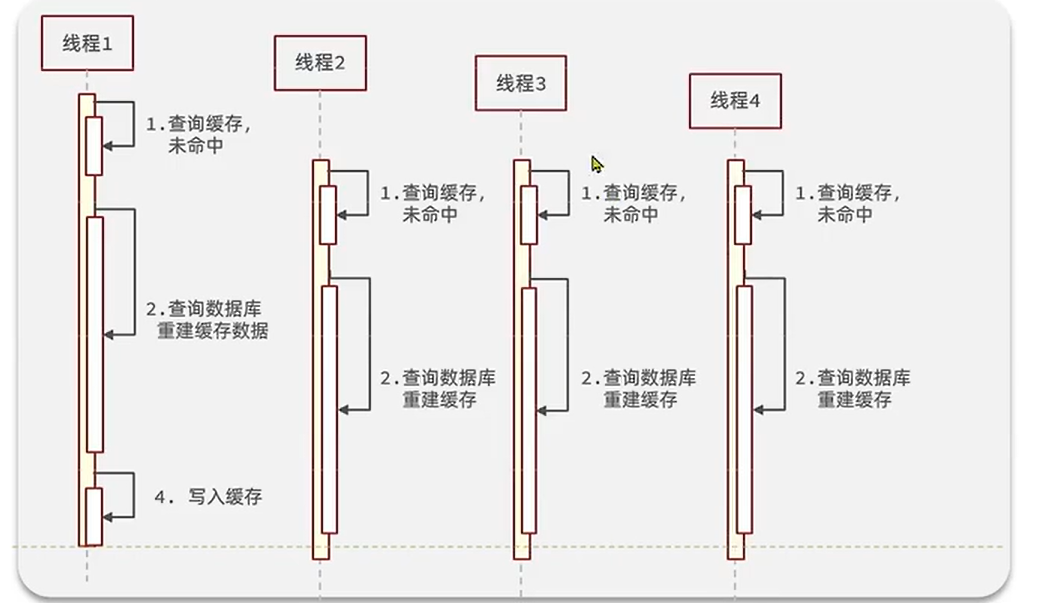
解决方案
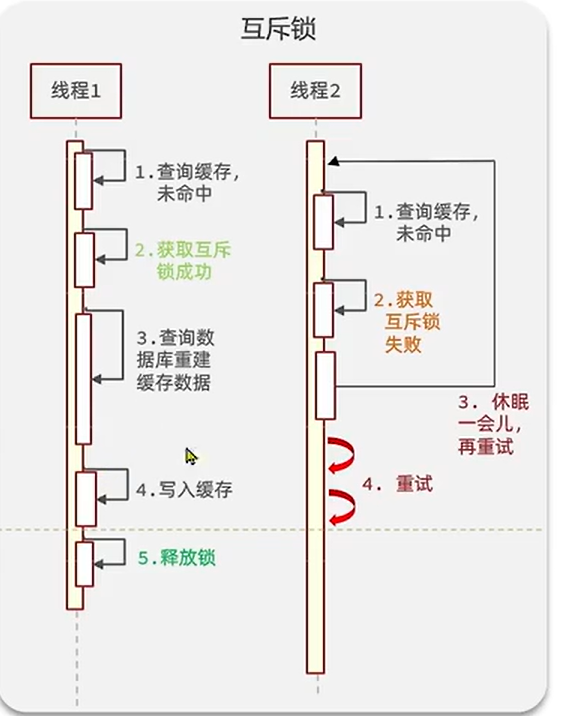
互斥锁
逻辑过期
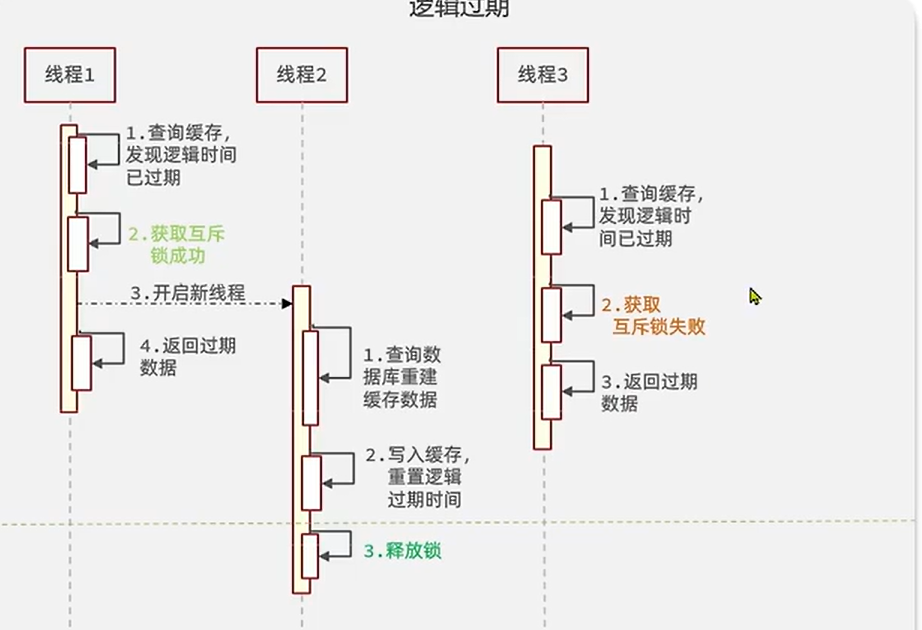
注意这个互斥锁和上面的,在用法上面的不同
总结
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的消耗 保持一致性 | 线程需要等待性能收到影响,可能有死锁的风险 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性,有额外的内存消耗,实现复杂。 |
实战
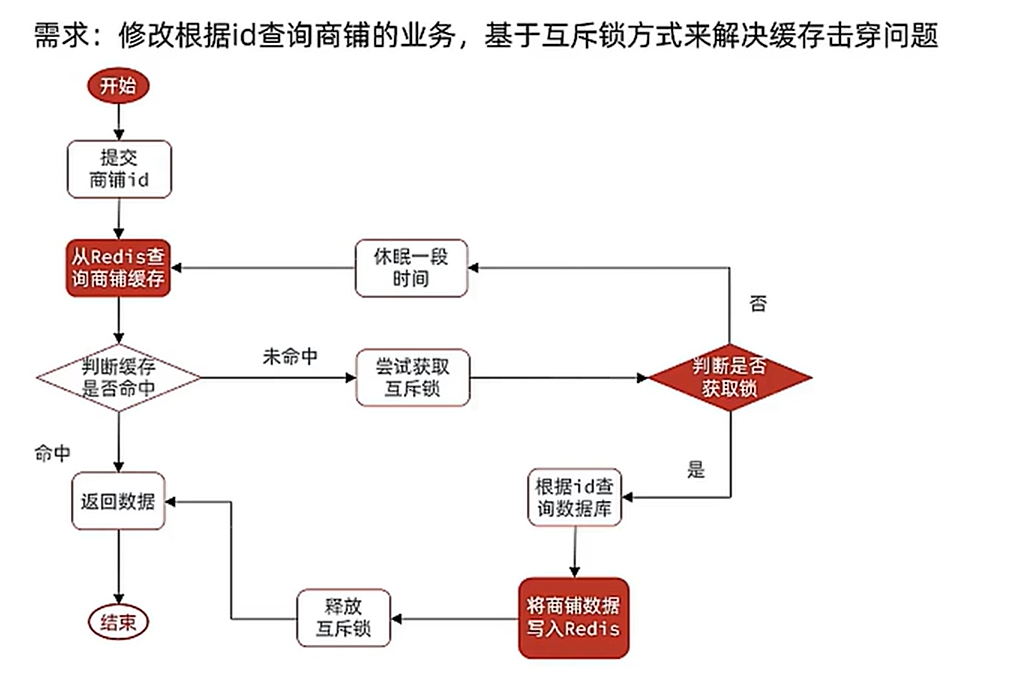
我们可以利用setnx, 来实习互斥锁。
热点key才会设计到 缓存击穿
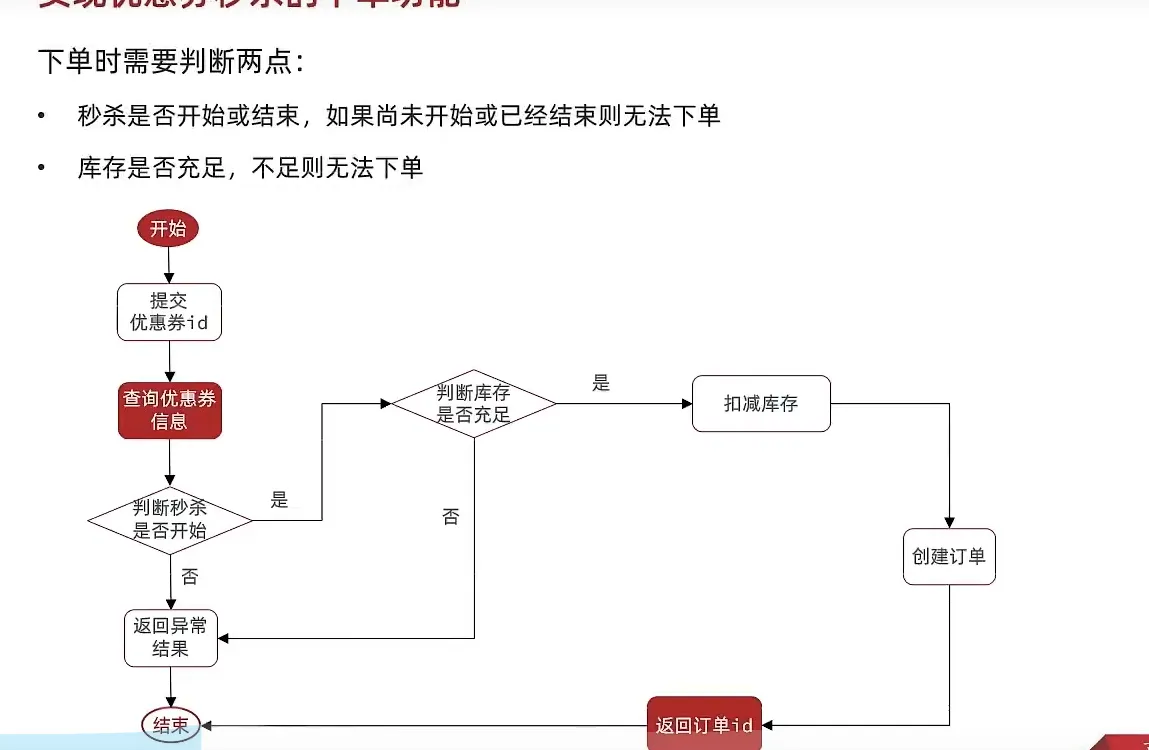
进一步实战 - 秒杀
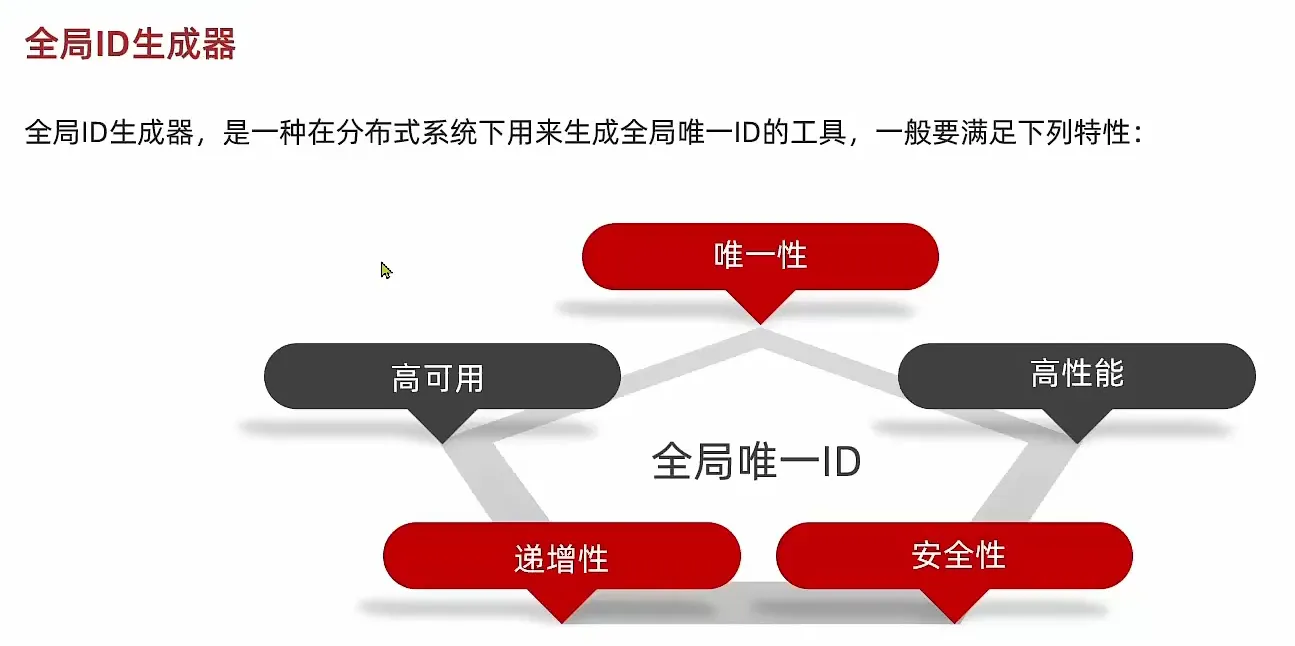
全局唯一ID - 生成器

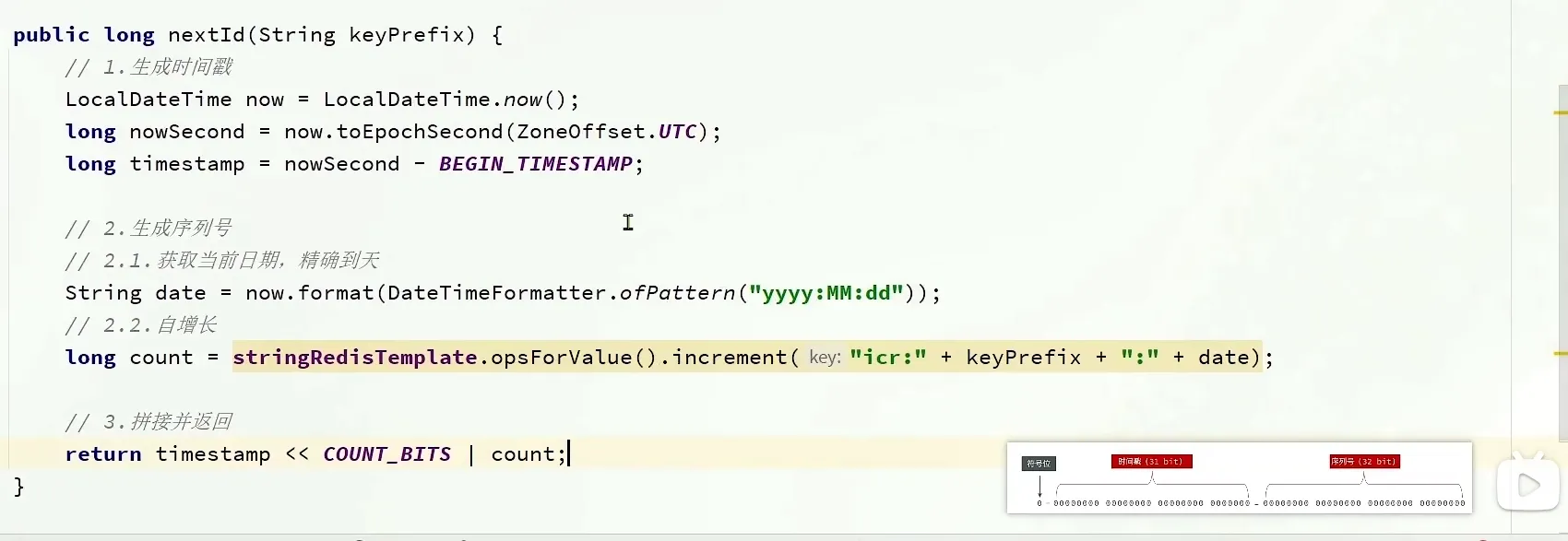
- 更新数据库的操作

多线程并发问题
- 我们使用锁的方案的来解决这个问题
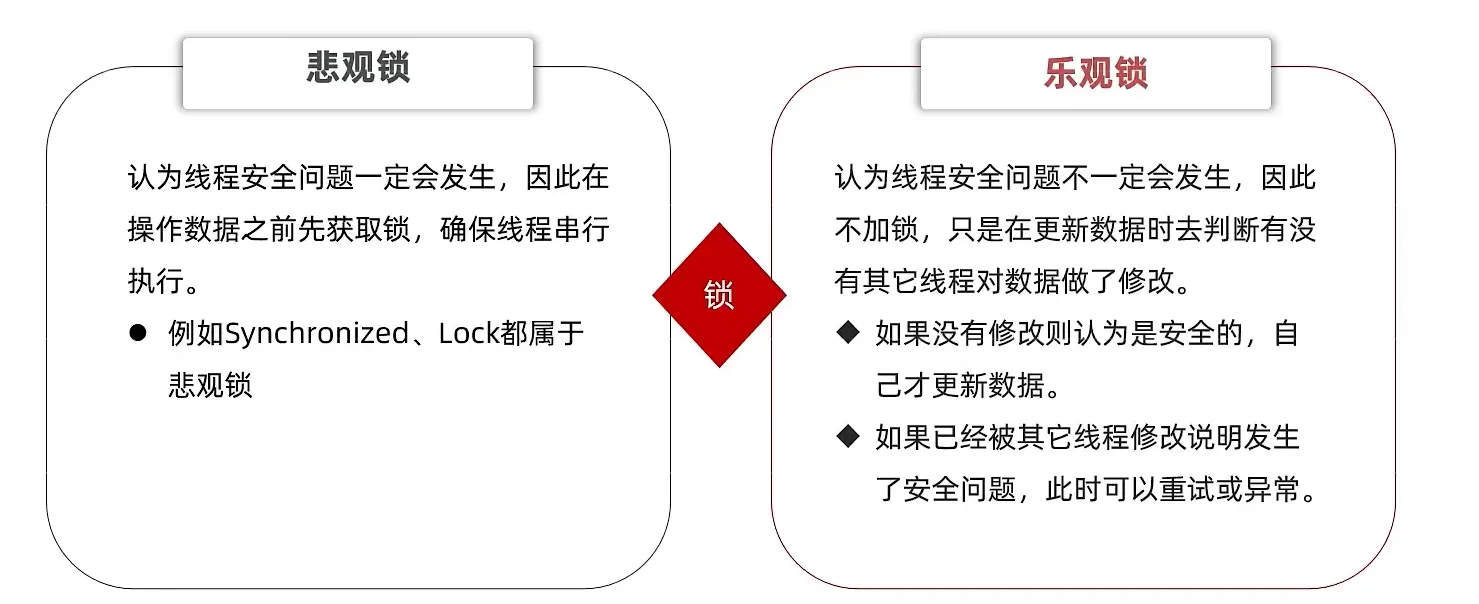
- 我们可以设置一个版本号
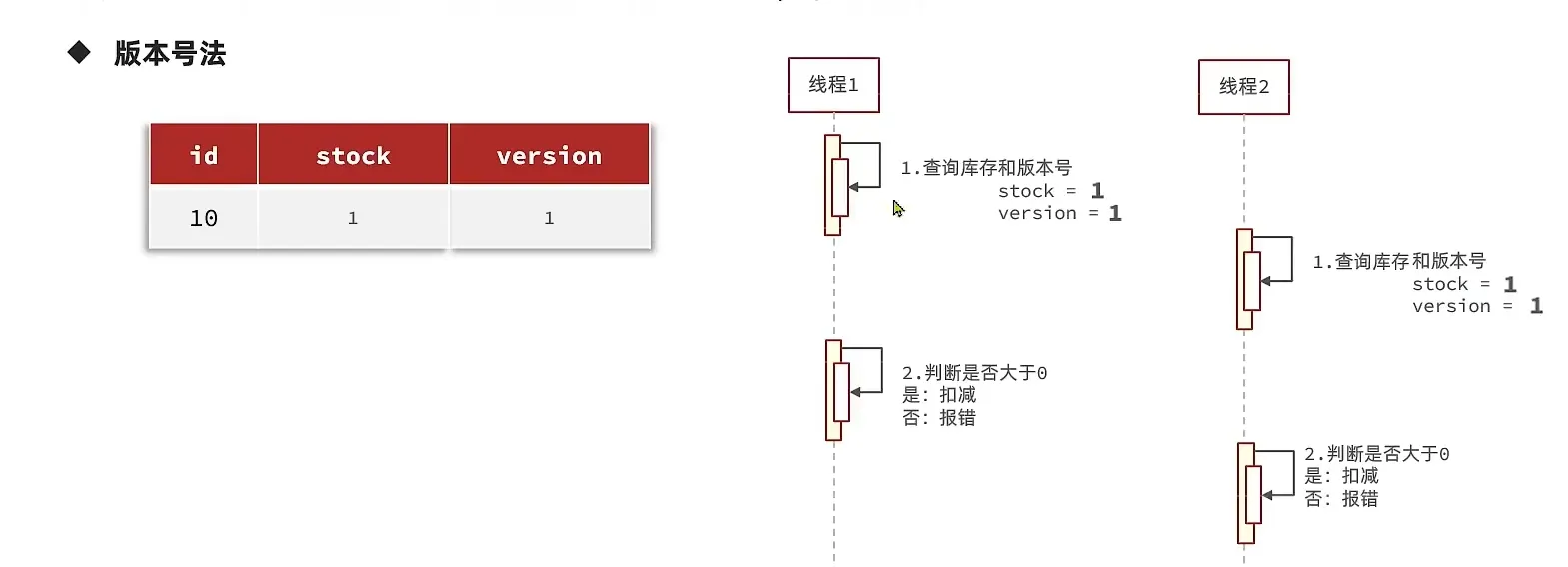
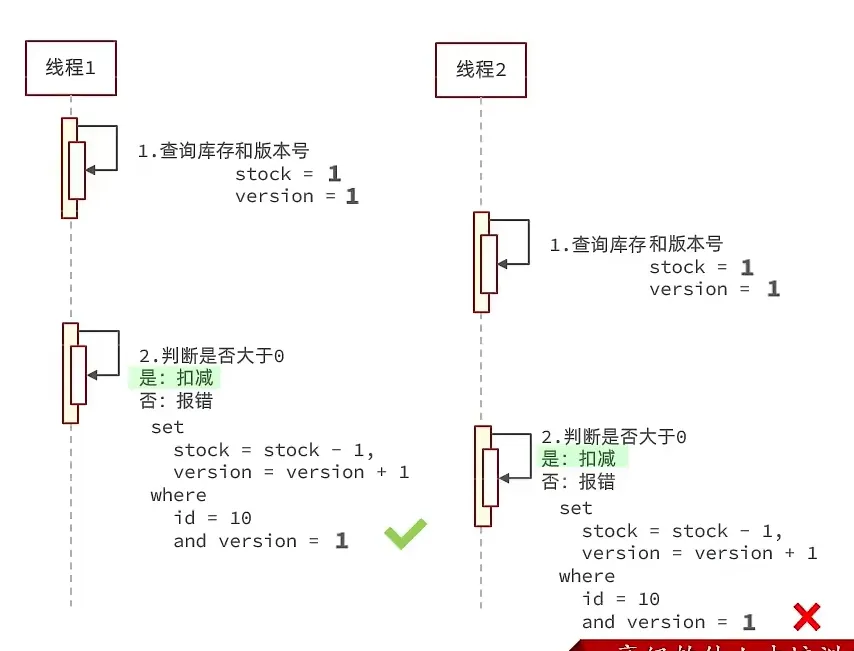
- CAS 法 (利用库存代替版本)
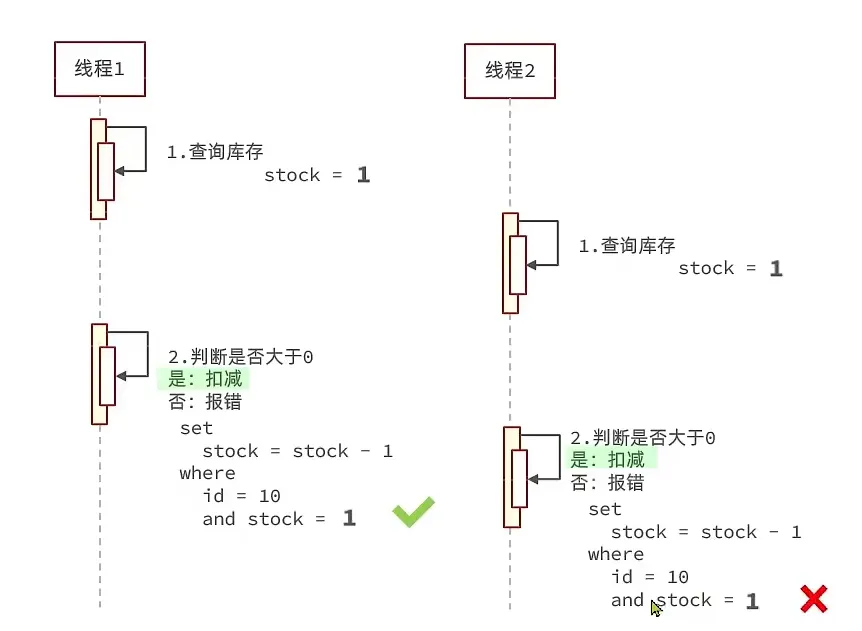
这里写sql的时候where stock > 0是没问题的,因为update语句在执行的时候会加行锁,即使多线程高并发,也不会出现多个线程同时执行update,因为加了行锁

但是这样还是有点问题, 所以我把库存换成大于0
1 | boolean success = seckillVoucherService.update() |
增删改会自动加锁数据库,查只有在串行化才回加锁
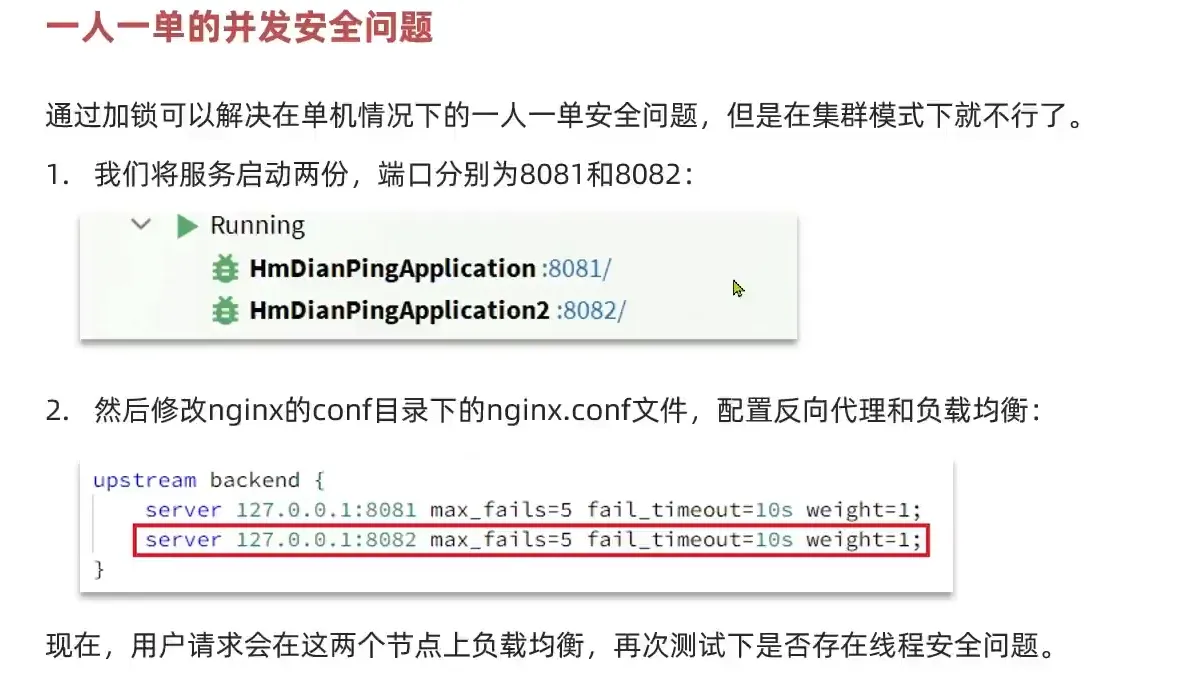
一人一单
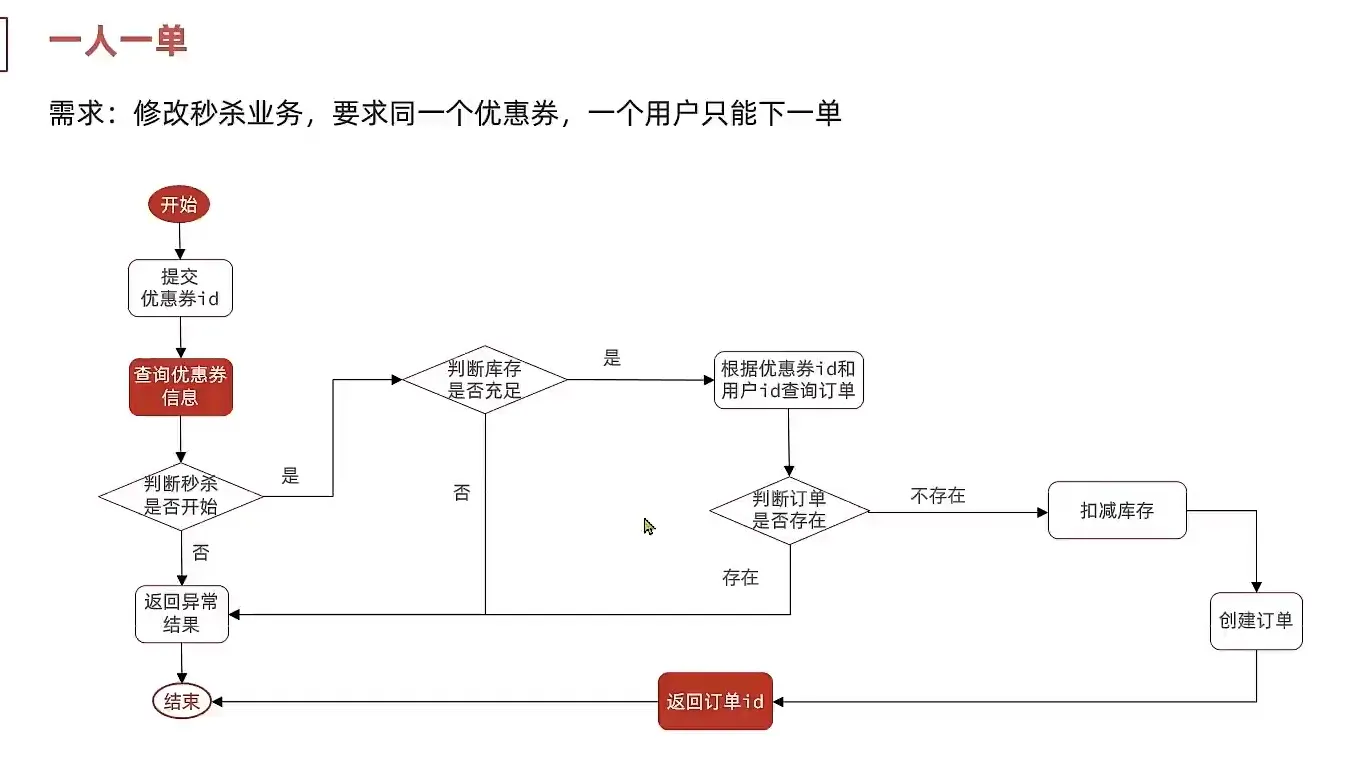
我们发现如果相同用于同时访问, 他会出现一人用多单
我们需要对一对代码加上代码块

然后加上这个intern 使得拿取字符串在常量池中拿取
为了解决事务传递问题, 我们来写下面的方法
引入依赖
1 | <dependency> |
- 在启动类加上一个注解
1 |
- 我们需要使用代理对象来调用下面的方法 而不是直接调用下面的方法, 两个含义是不一样的
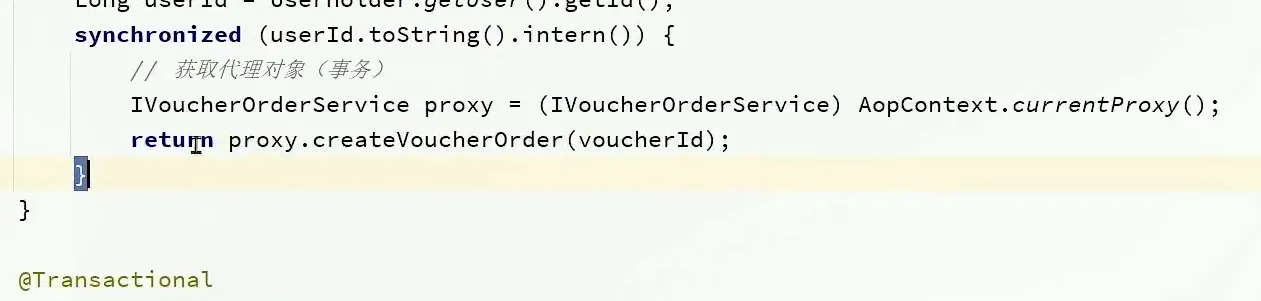
集群解决并发问题
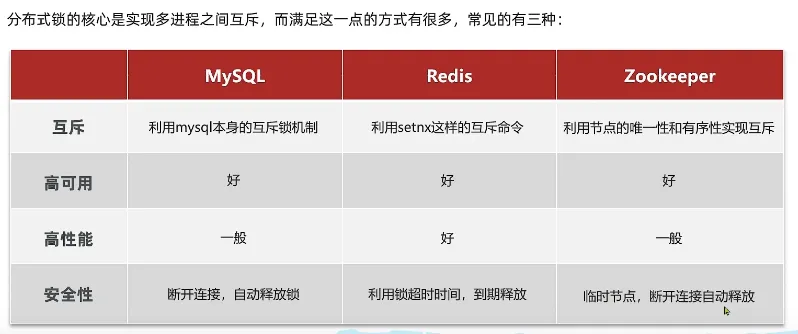
分布式锁
在集群模式, 分布式 下, 有多个jvm 存在, 每一个jvm 都有自己的锁, jvm之间的锁互相隔离
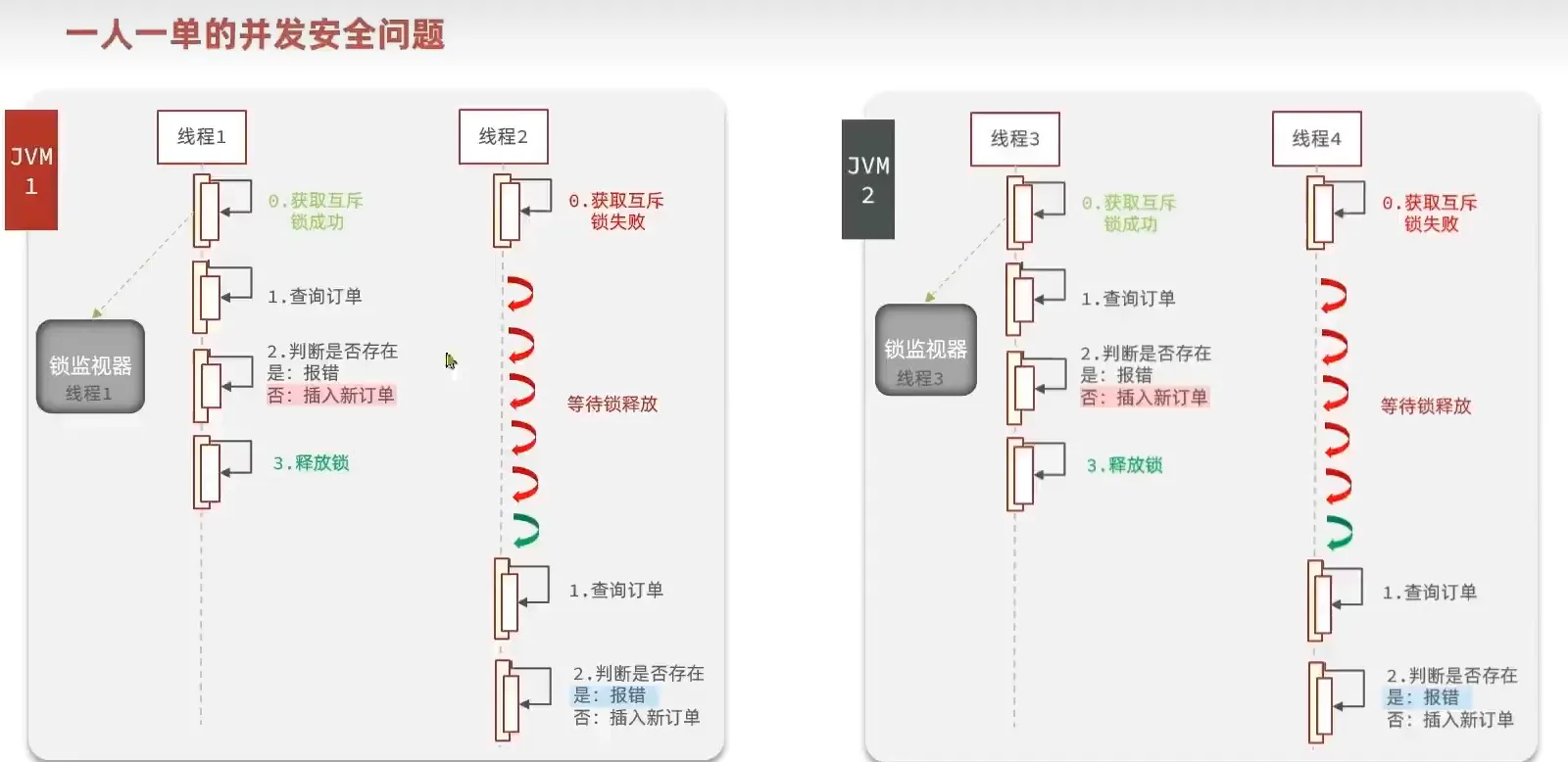
所以我们需要使用可以跨jvm锁的方式来解决这个问题。
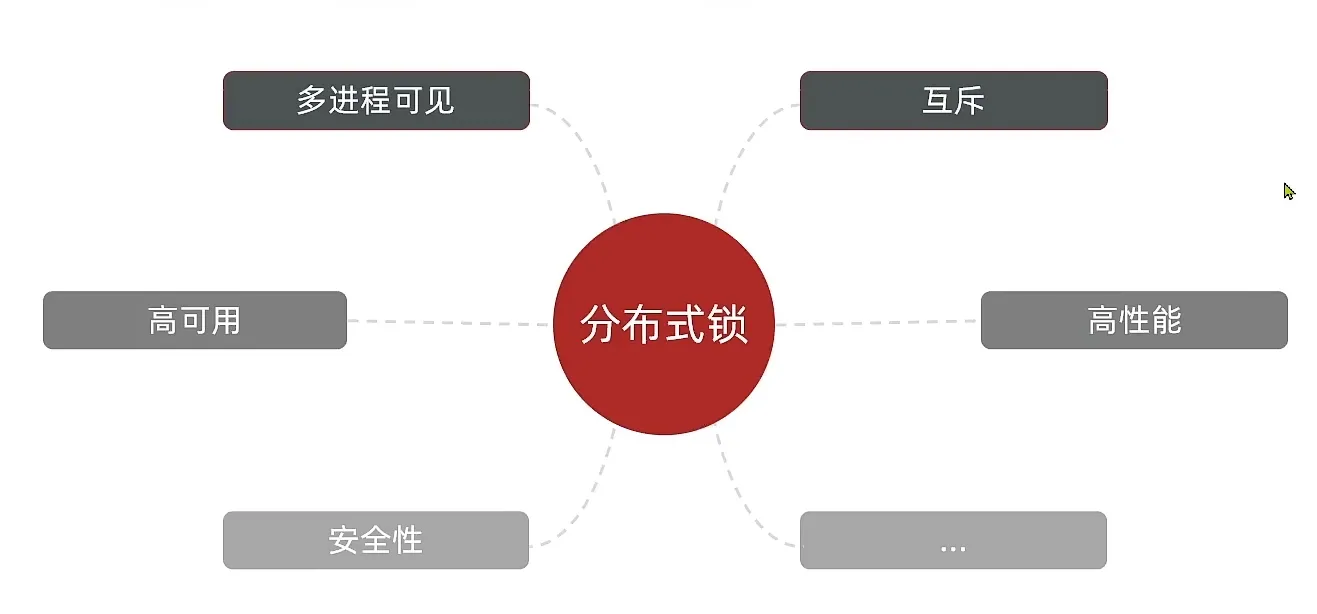
分布式锁的定义
- 满足分布式系统或者集群模式下多线程可见并且互斥的锁
setnx 只有在 数据存在的时候,才会成功, 并且可以通过设置超时时间,到期释放, 可以解决安全性的问题
实现分布式锁

但是如果在 过期操作执行之前, setnx 执行之后, 出现业务故障, 那么要怎么办呢?(如何实现原子操作)

我们使用这种方式就可以保证它的原子性
当一个业务阻塞,造成消耗时间太长, 会出现下面的问题
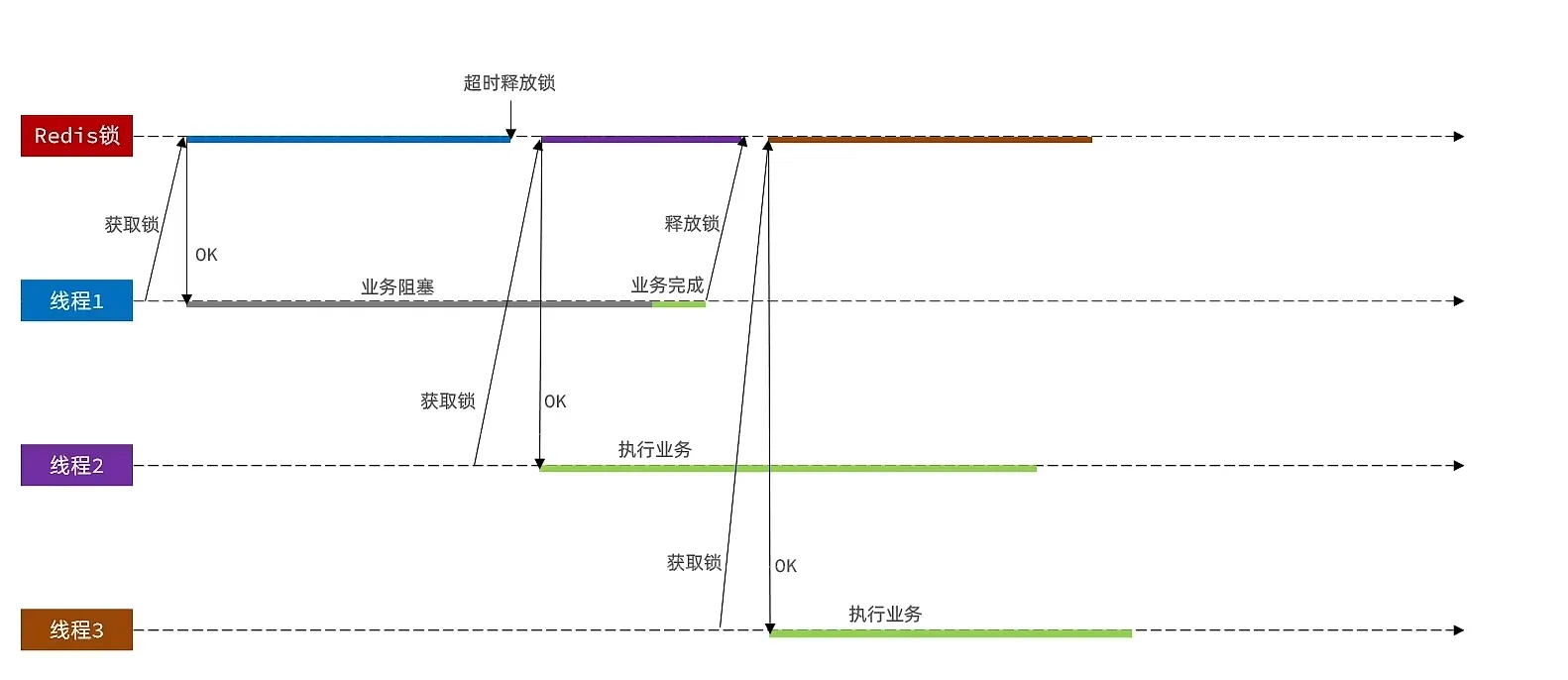
我们可以在释放锁之前,进行判断, 叫做锁标识
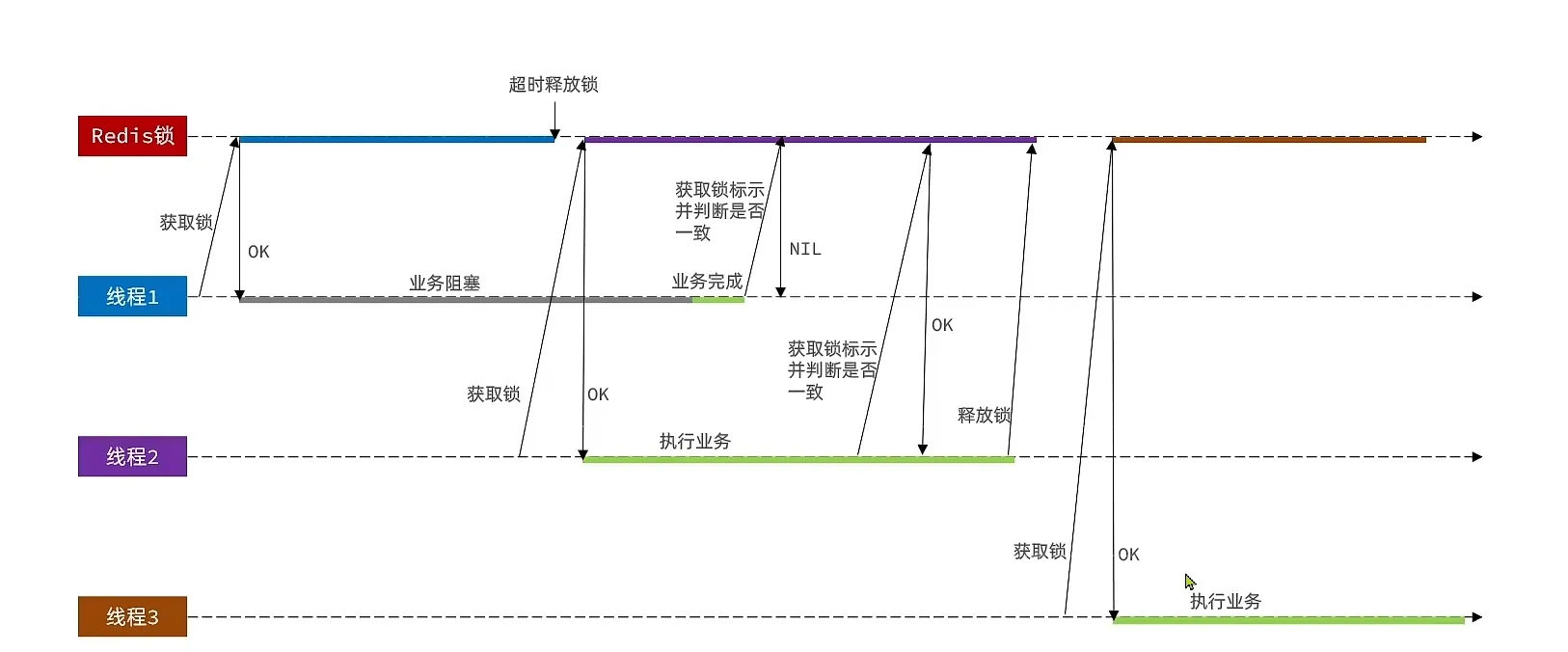
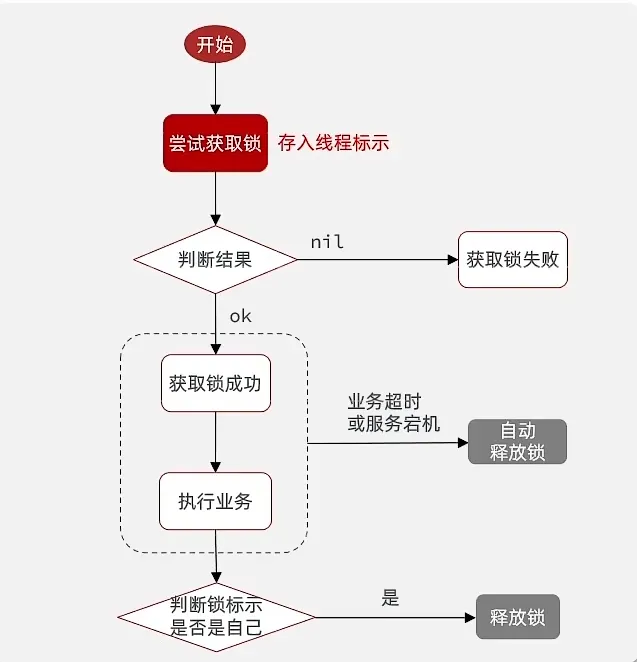
- 我们把他改进为这样

Lua 解决误删问题
使用lua 脚本 就可以解决 多条redis 的原子性
lua 调用 redis 的脚本如下

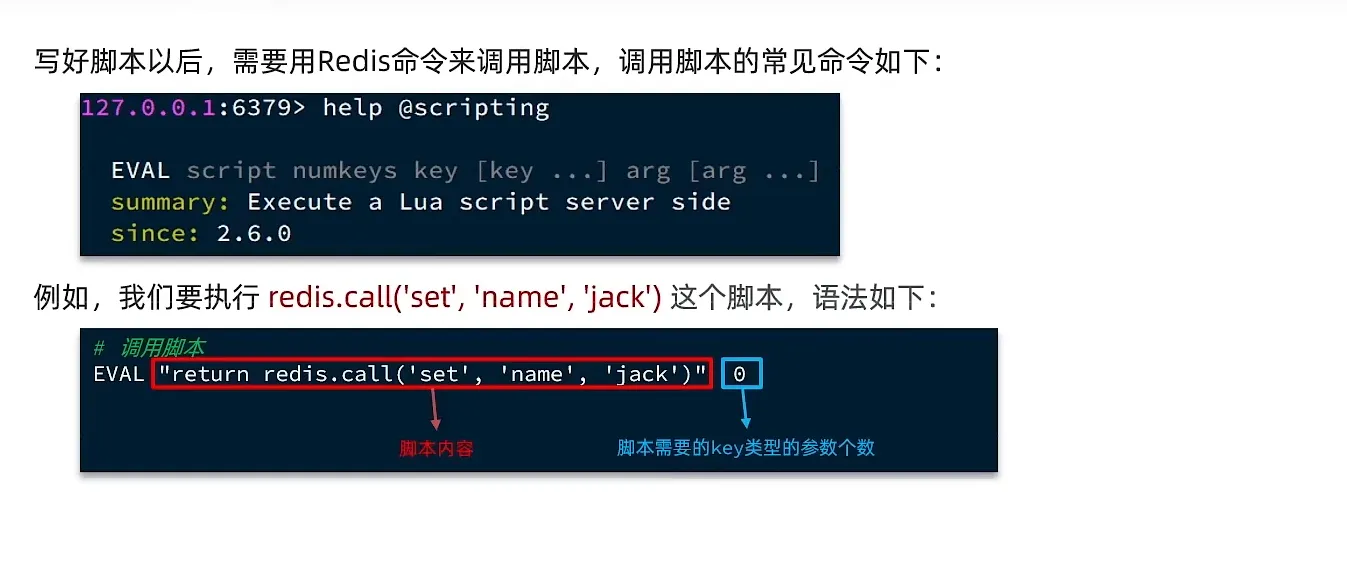
如果不想要写死参数 我们就用下面这个
在lua 语言中 下标的参数从 1开始

注意这里的KEYS 和 ARGV 需要大写。
1 | -- 这是注释的方式 |
- 在java 中使用lua


Redission
- 基于 setnx 实现的 锁操作存在着下面几个问题


引入依赖以及 配置客户端
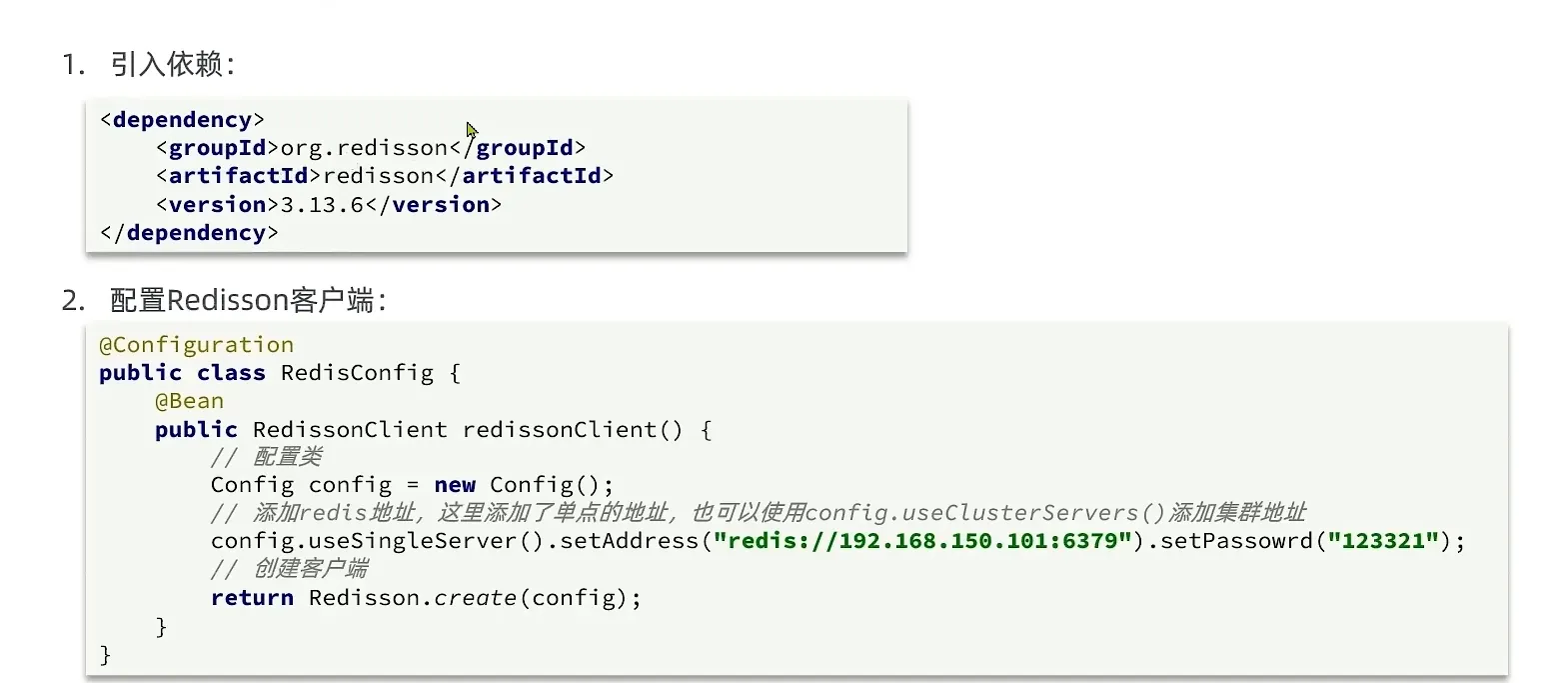
1 | <dependency> |
- 配置类
1 | package com.hmdp.config; |

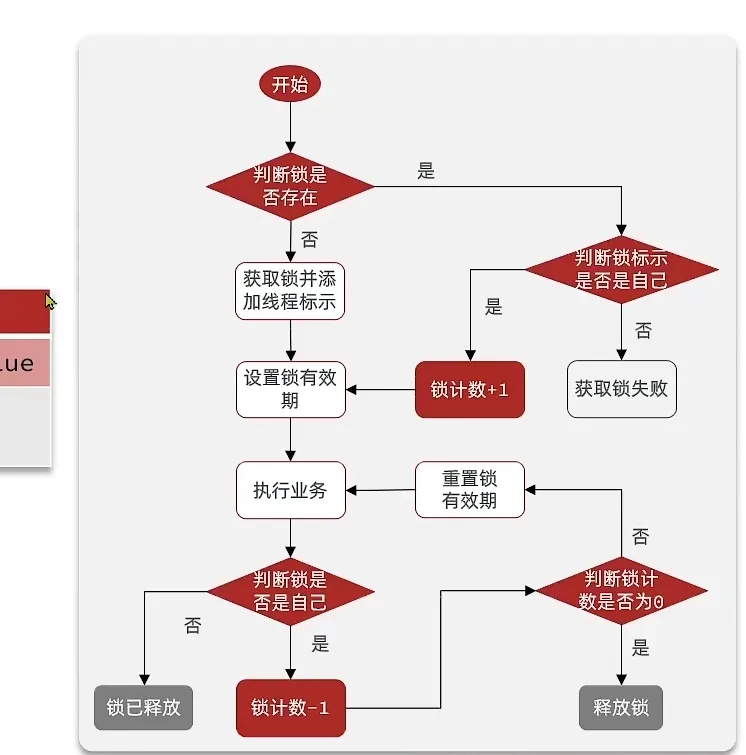
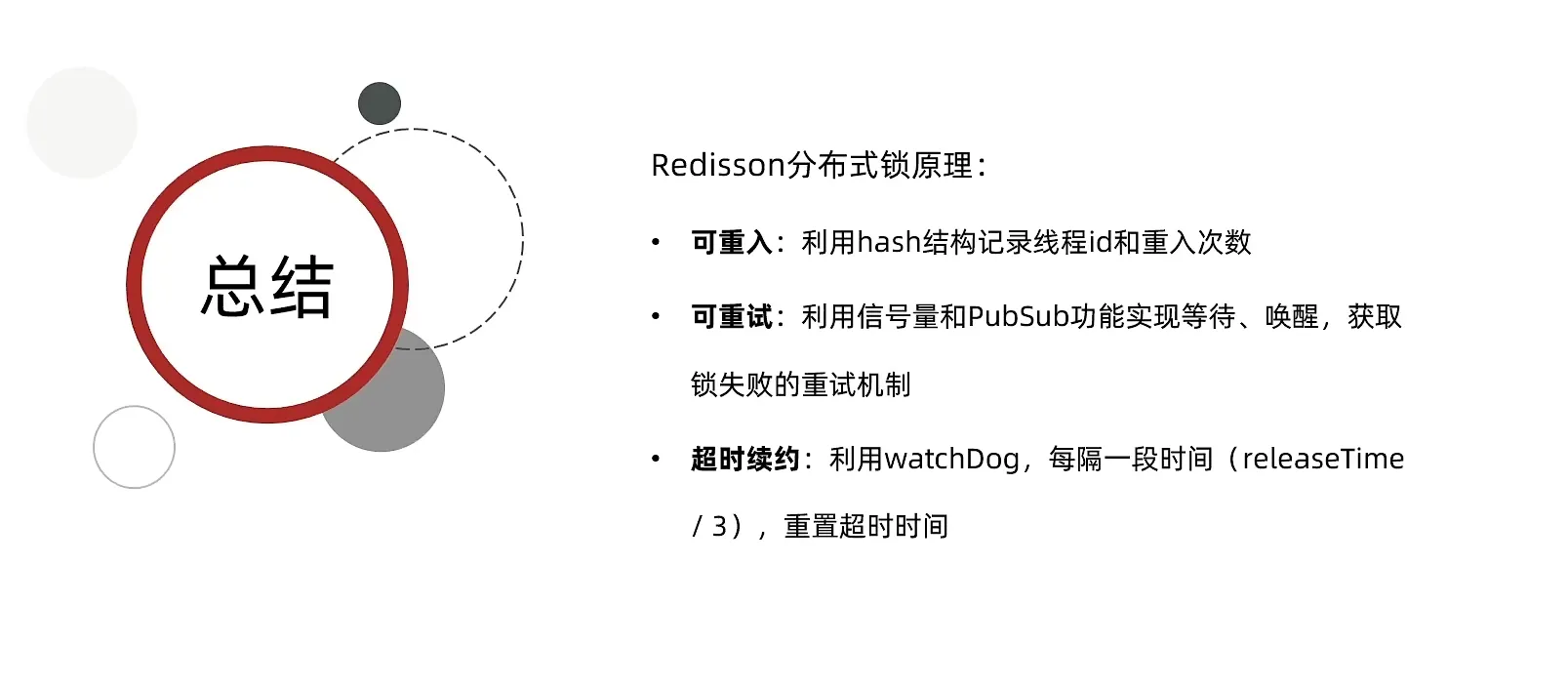
Redission 的可重入锁原理
利用哈希结构, 记录重入次数
这样就不用 不是原本的互斥
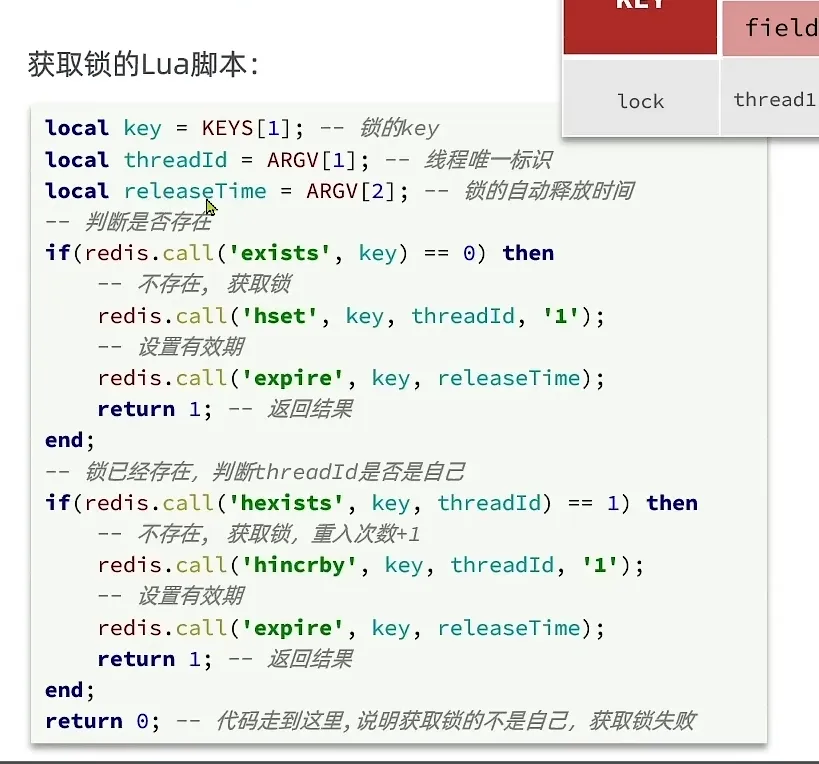
- 获取锁的Lua 脚本
释放锁的脚本

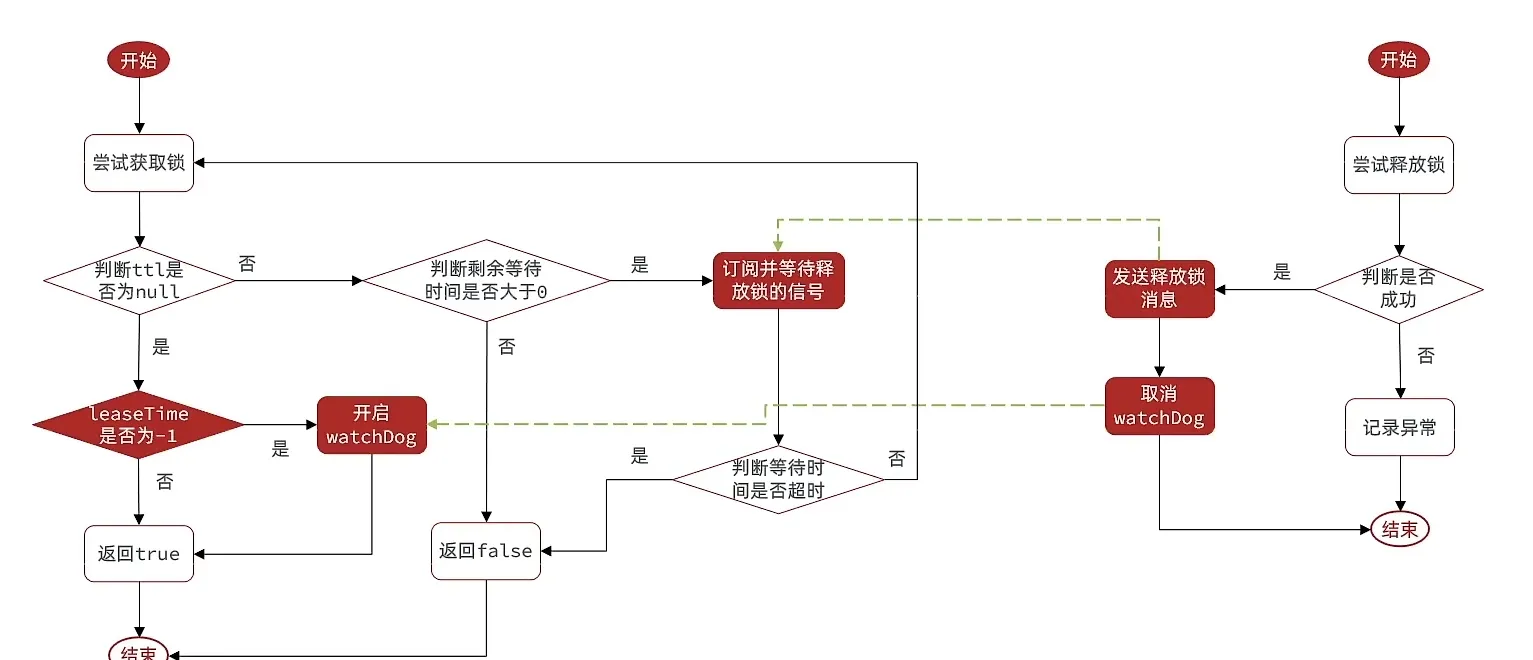
- 这个地方 非常难懂, 建议多看
waiting time 是 锁等待时间
leaseTime 是锁超时等待时间
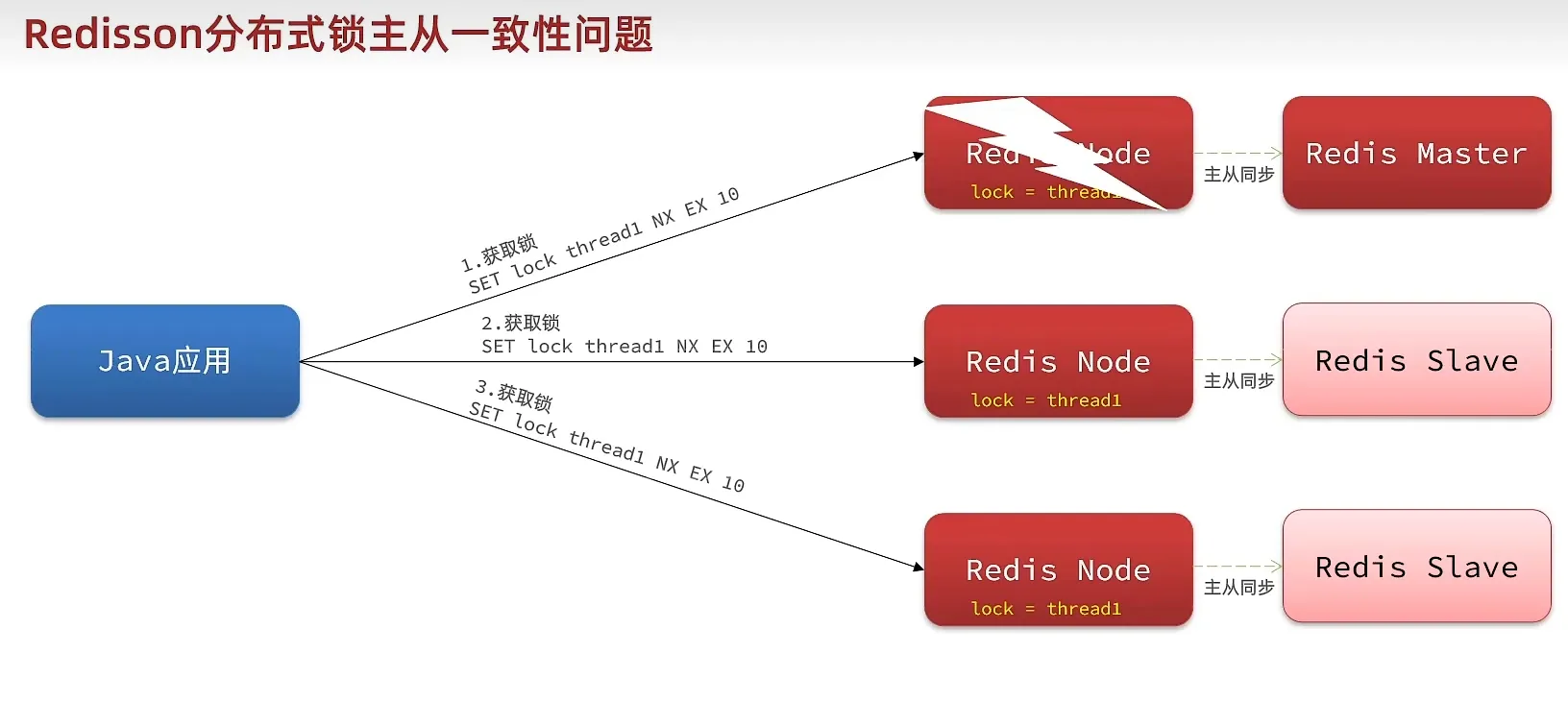
Redission 解决主从一致
- mulitlock

秒杀优化
- 优化流程
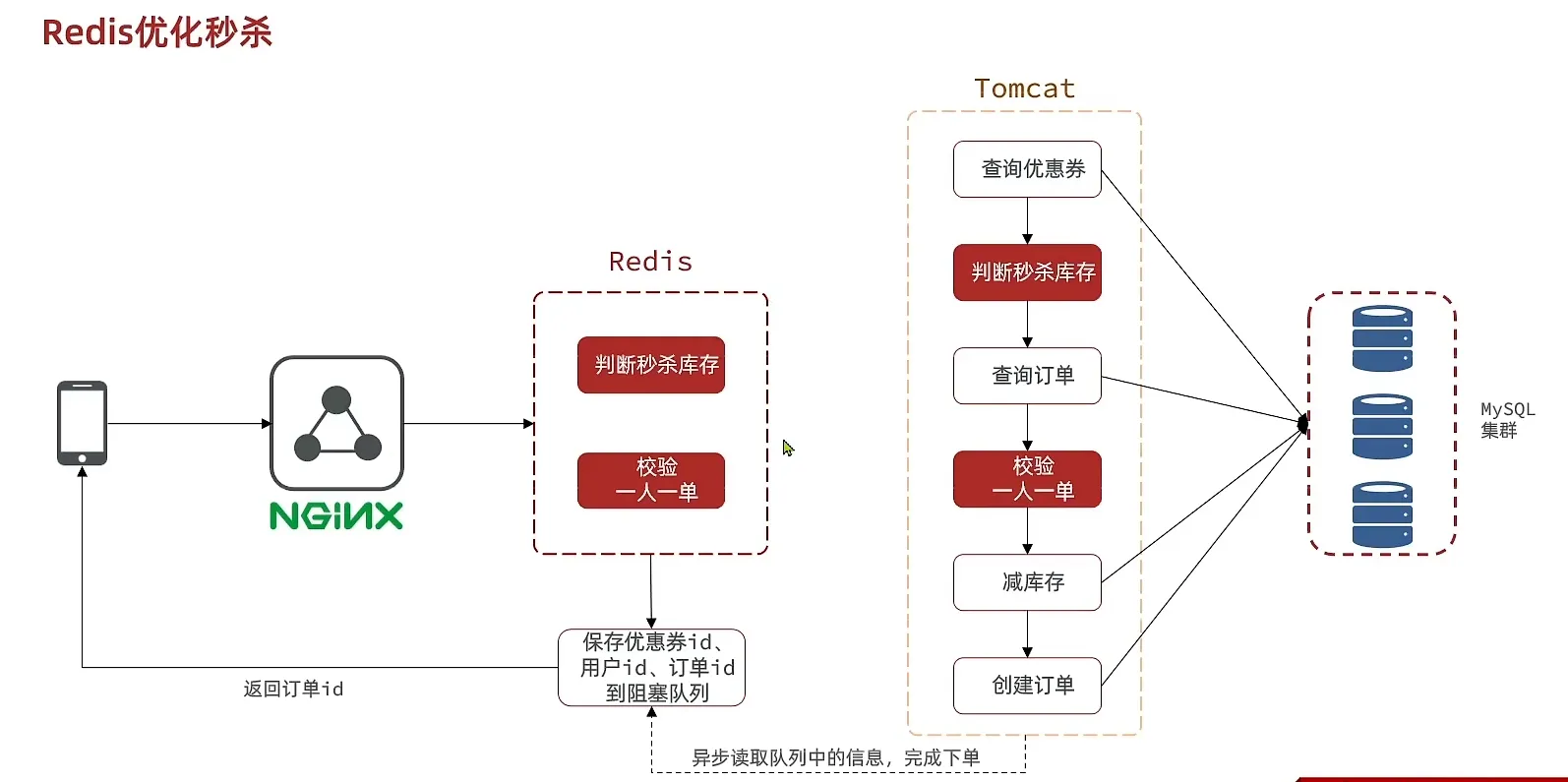
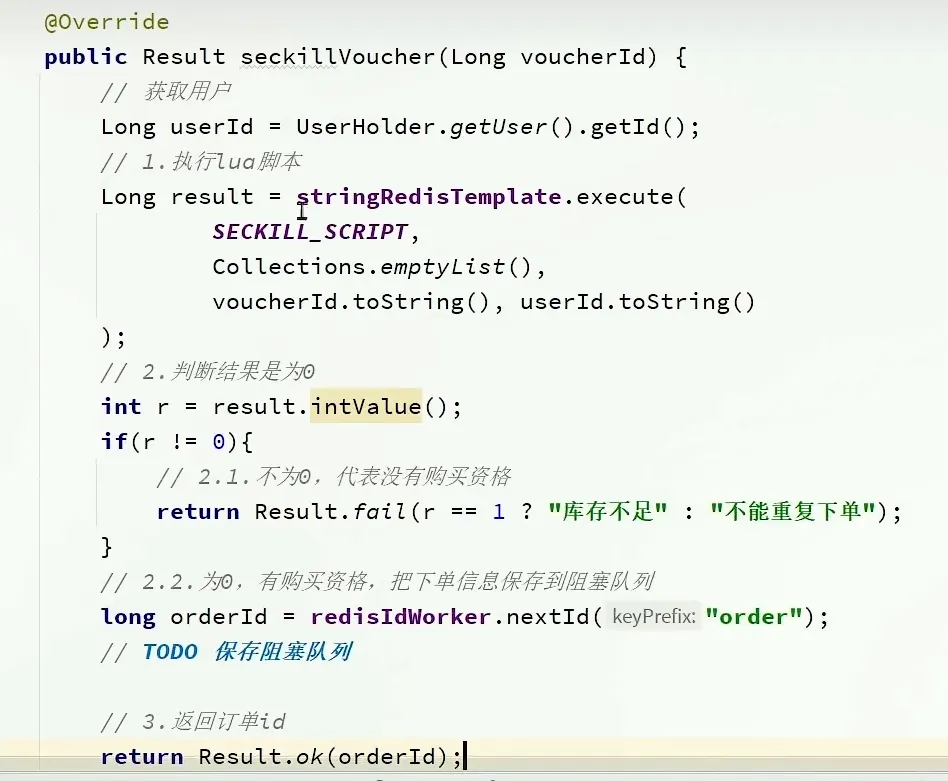
- 判断有没有购买资格
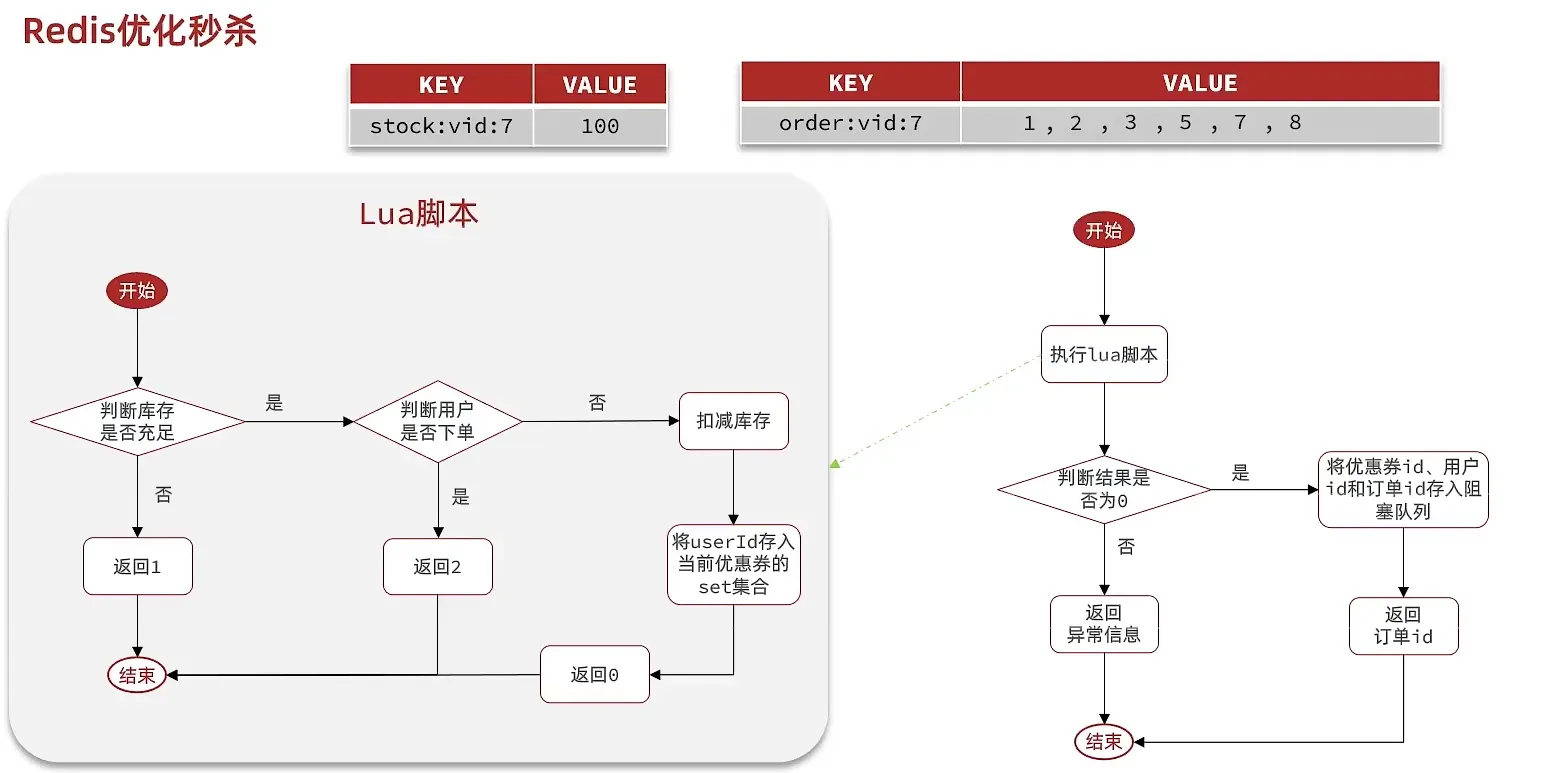
使用redis 记录 情况, 然后适当时间 存入到数据库中
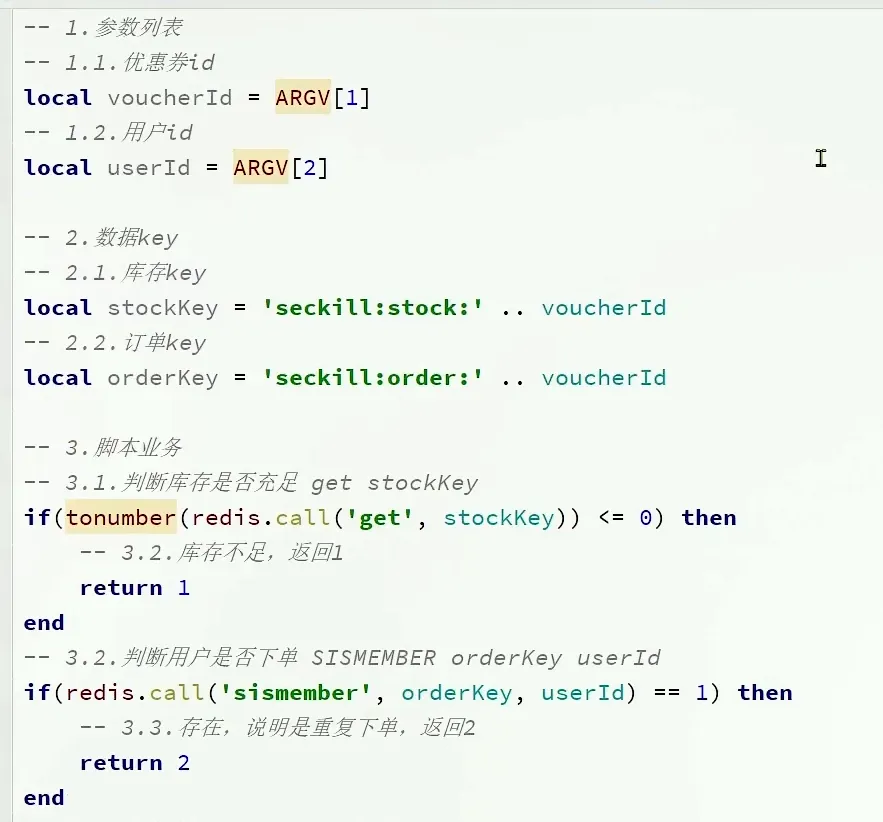
- redis 的redis 判断是否存在 SISMEMBER
- tonumber 将string 转变为number 类型 (lua脚本)

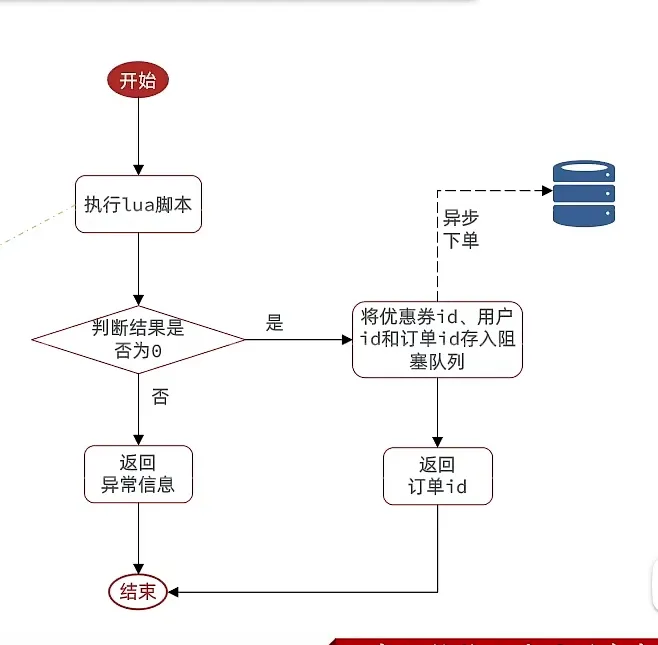
异步发送消息


声明阻塞队列和 线程池
@PostConstruct 可以用于 类初始化之后执行的任务
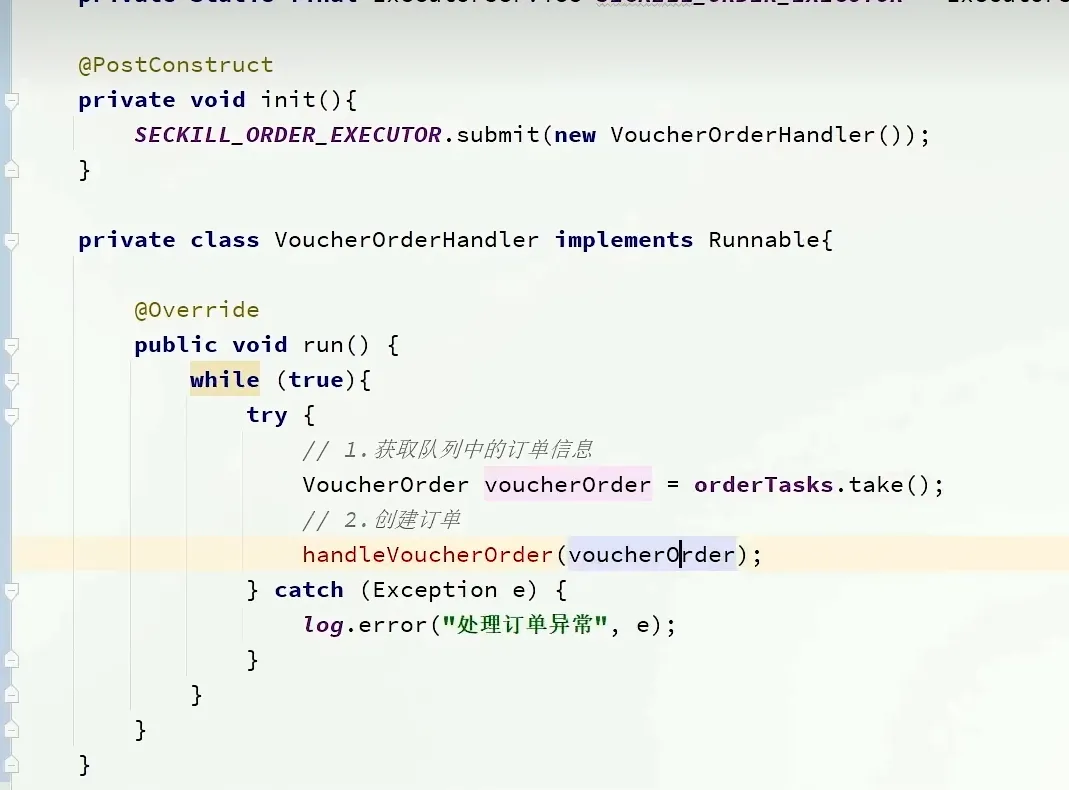
这里后面还是需要多看。
- 但是这里还会存在一些问题

消息队列

- List 结构
使用LPUSH,RPOP, RPUSH,LPOP, 方法
, 前面加上一个B, 就是可以阻塞的
1 | BRPOP l1 20 |

如果移除了 , 信息,但是 消费者没有对数据信息消费就会有点问题

- PubSub
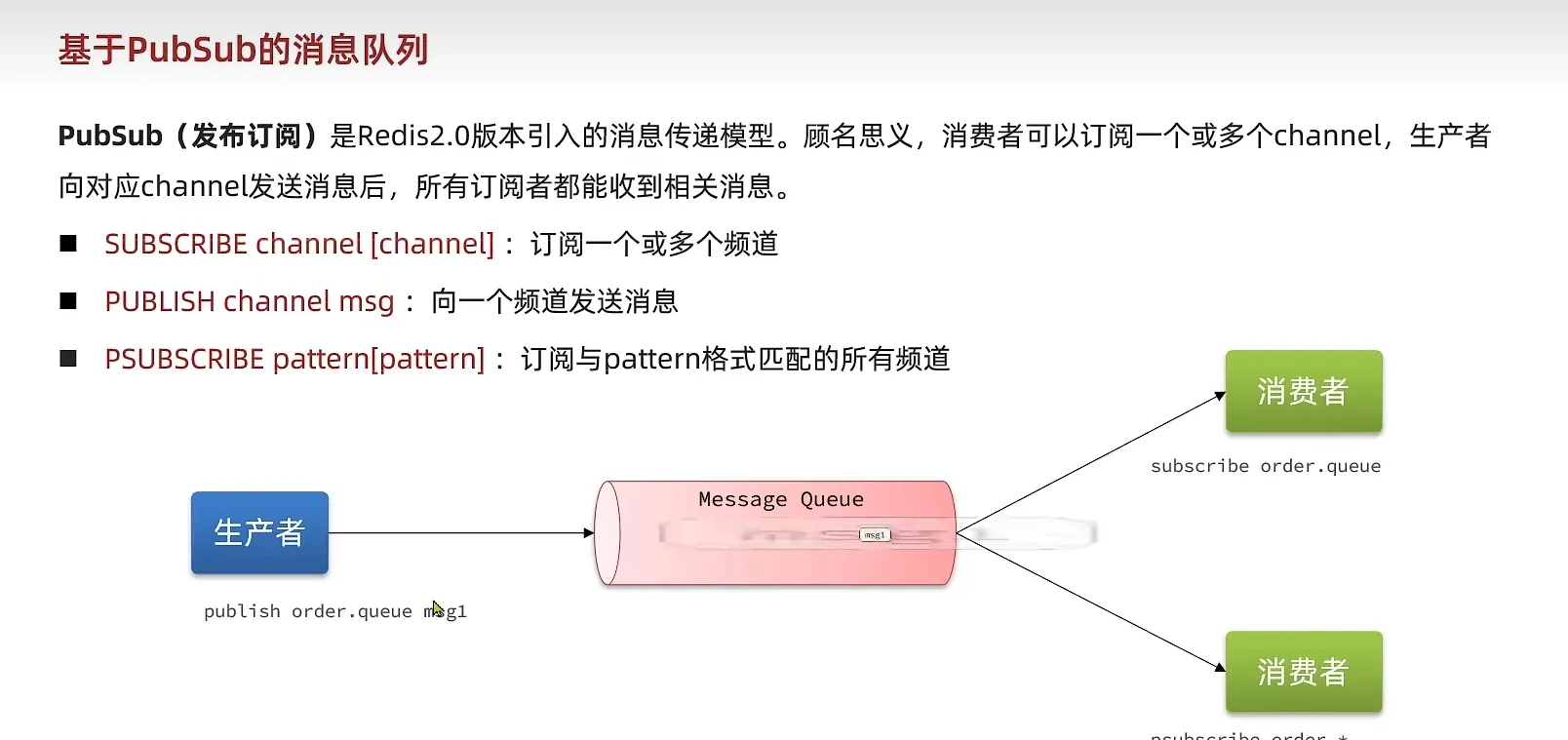
这是他的缺点
如果它发送信息的时候, 没有人接受, 这个消息就没有了

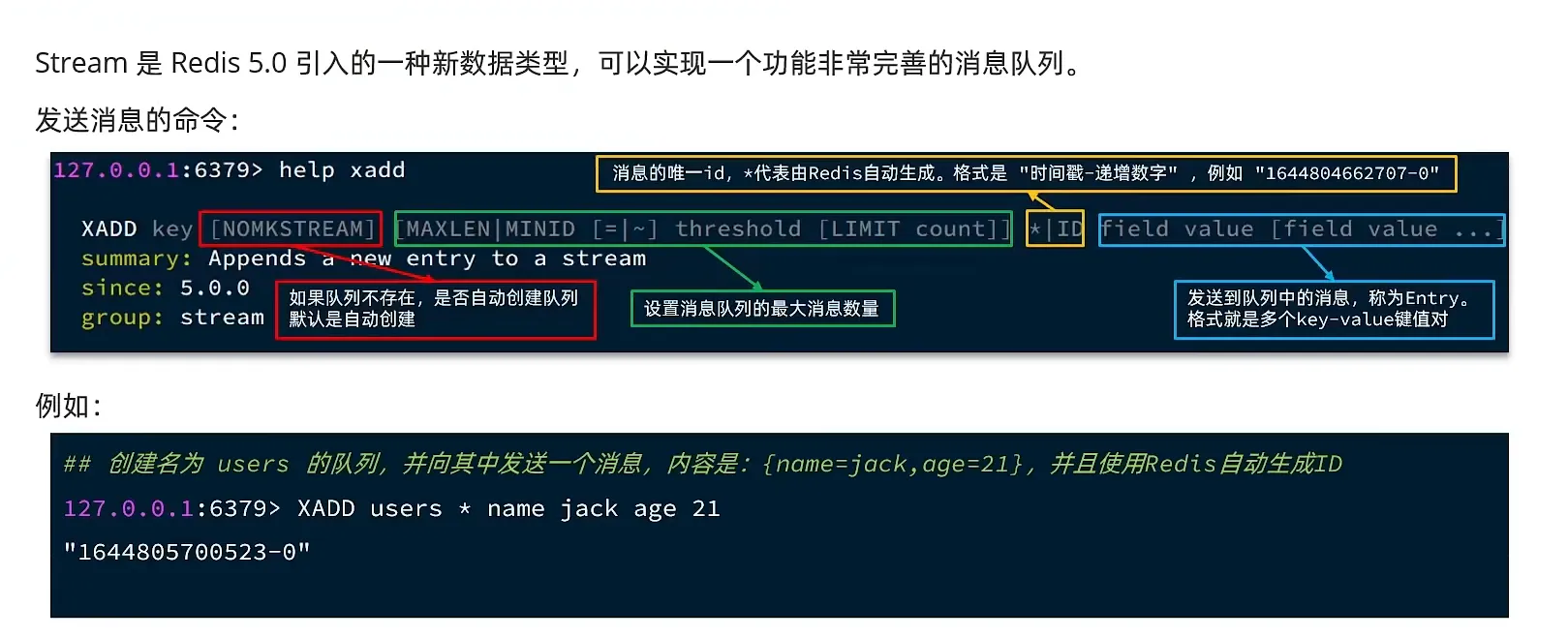
- Stream
发送消息
接受消息
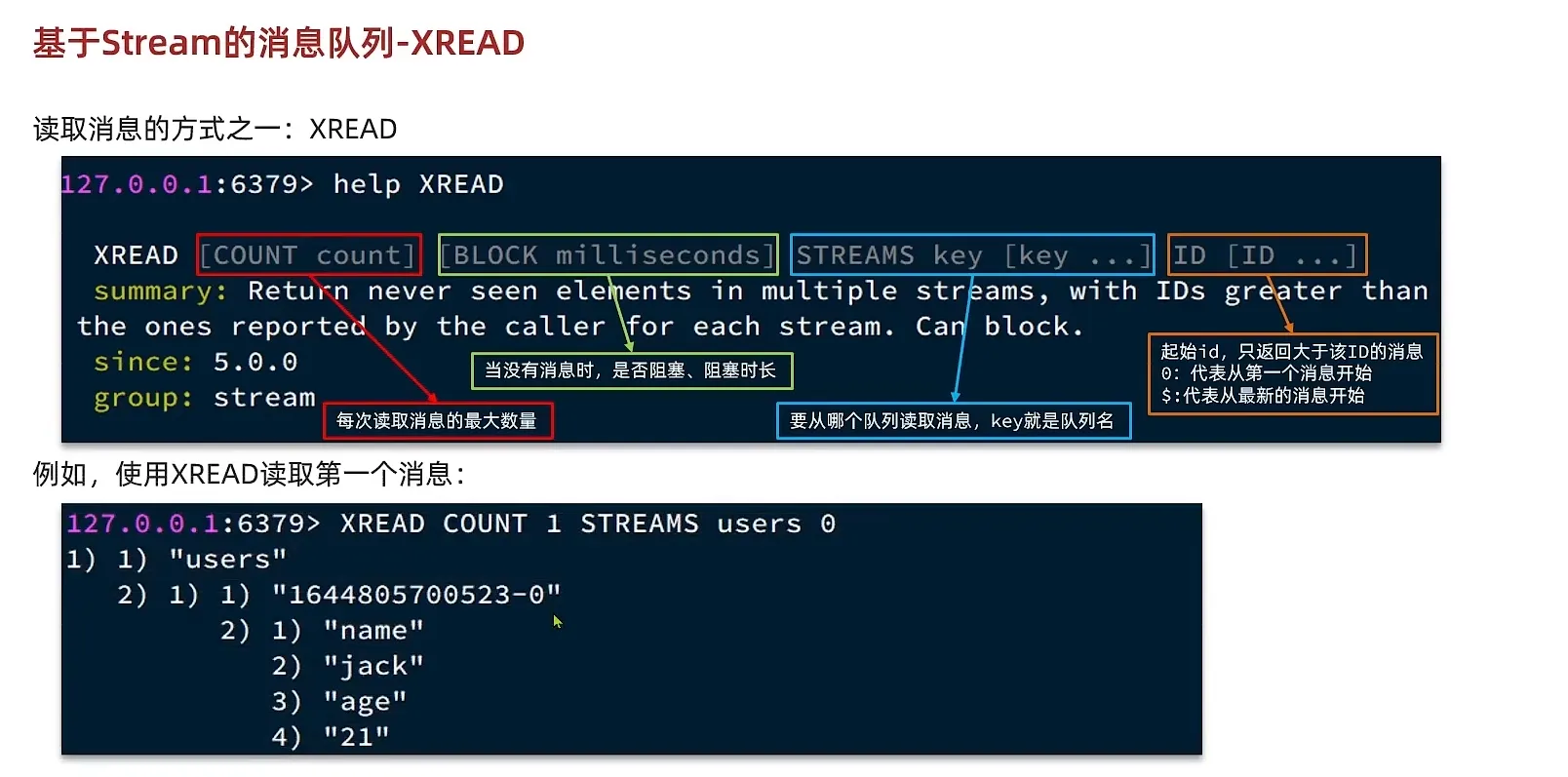
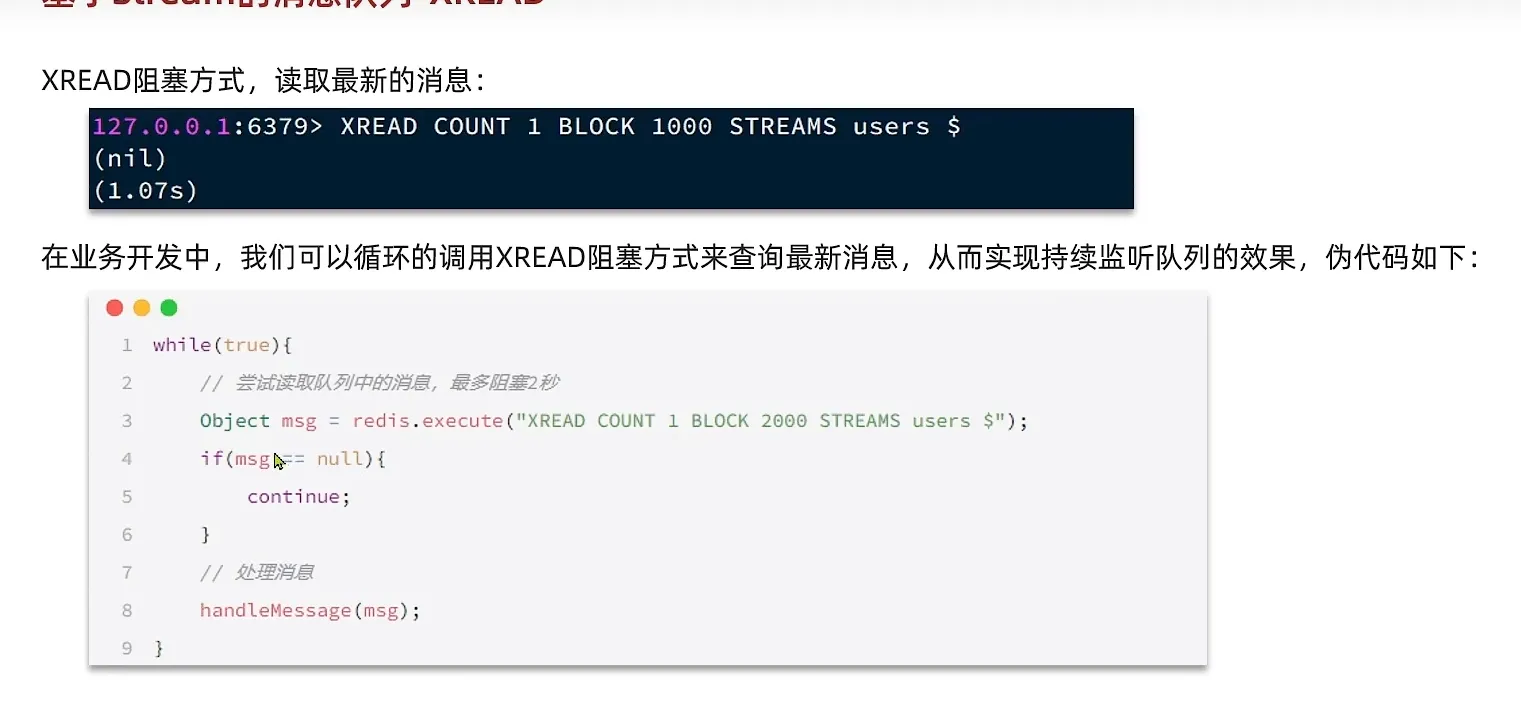
他有以下的优势和缺点
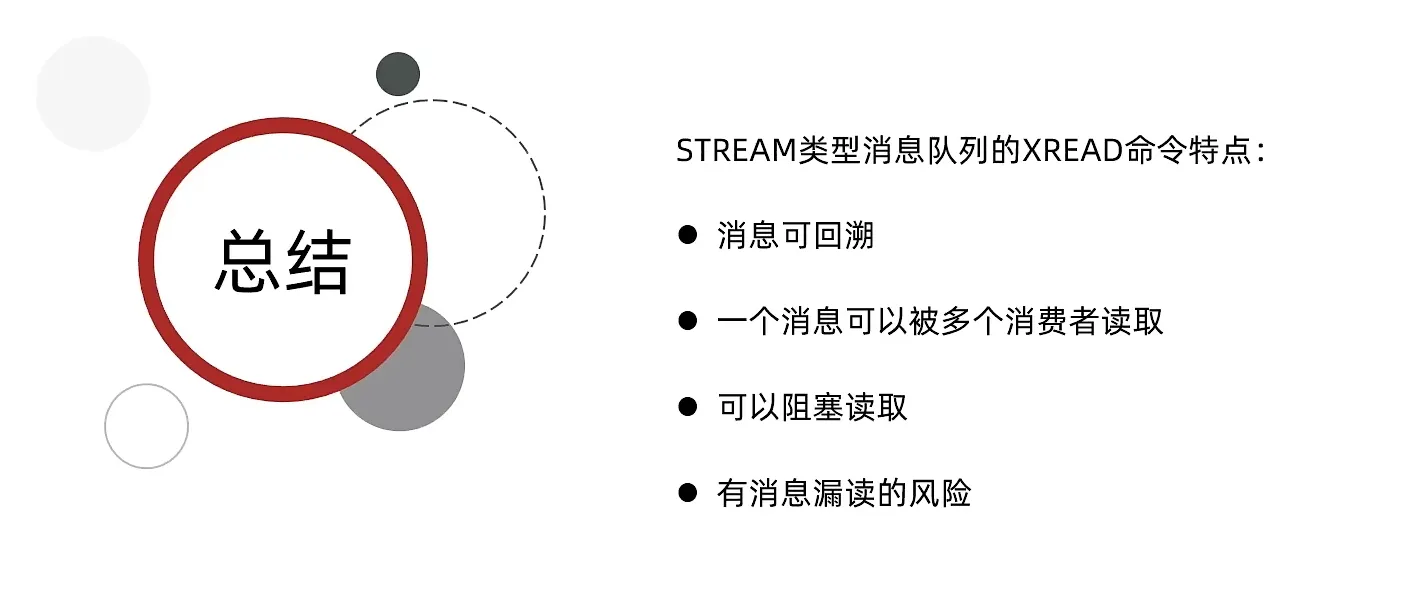
Stream-消费组

XGROUP CREATE key groupName ID [MKSTREAM]


在一个组中, 被其他消费者消费的, 对于另一个组就是被标记的东西。


- 创建 stream 组

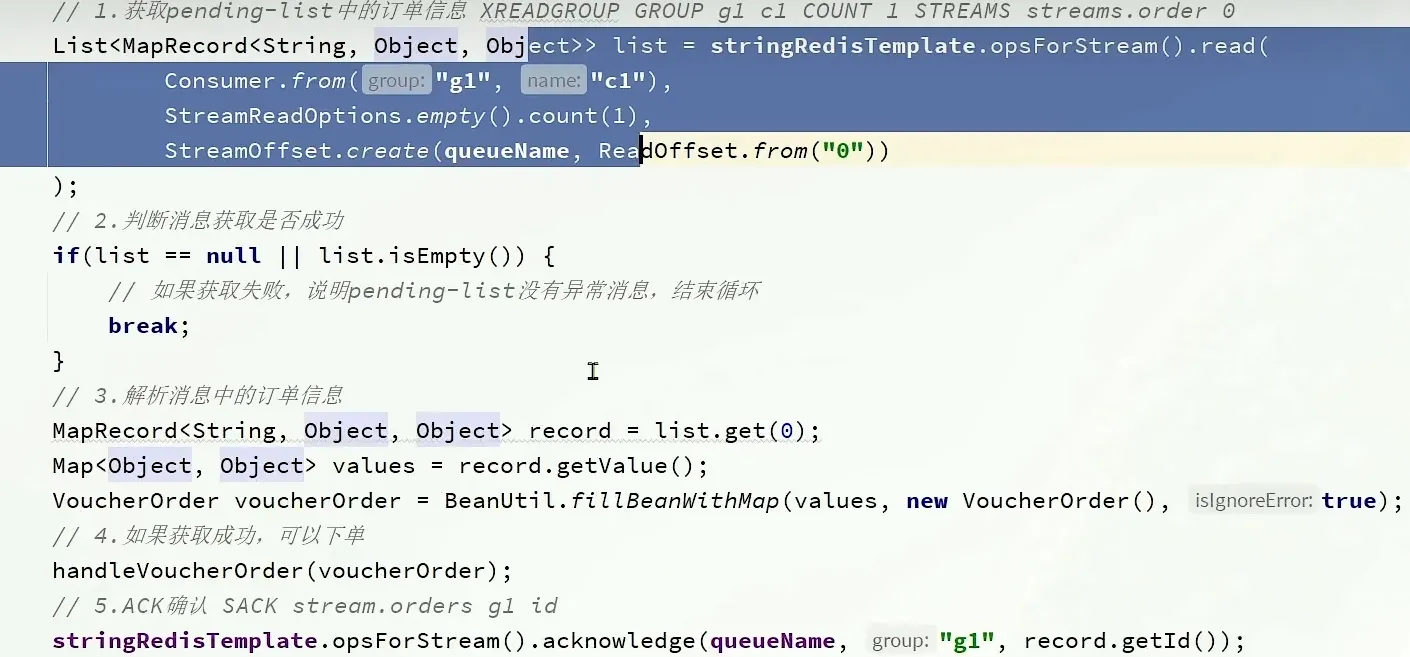
消息处理的流程
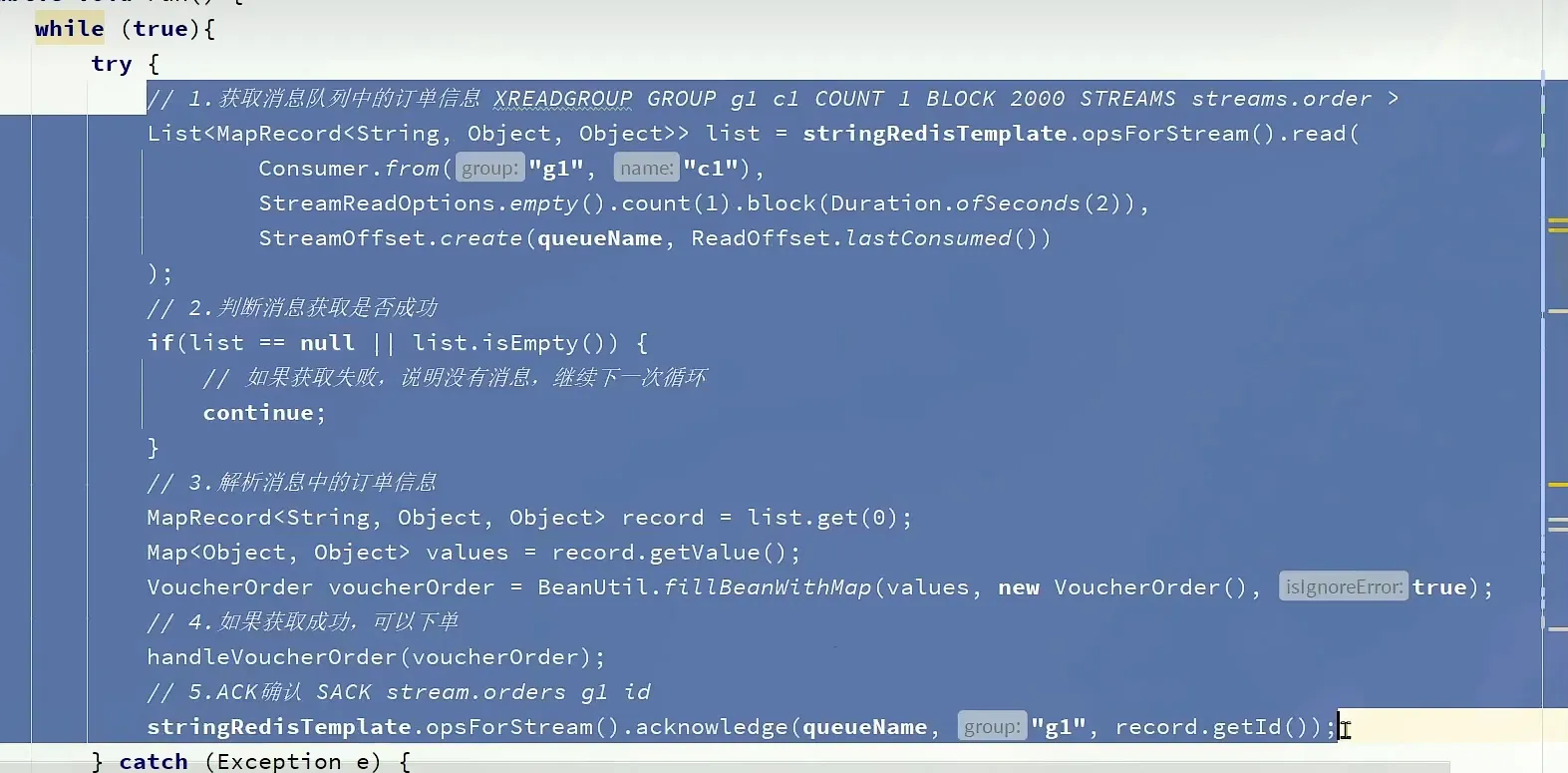
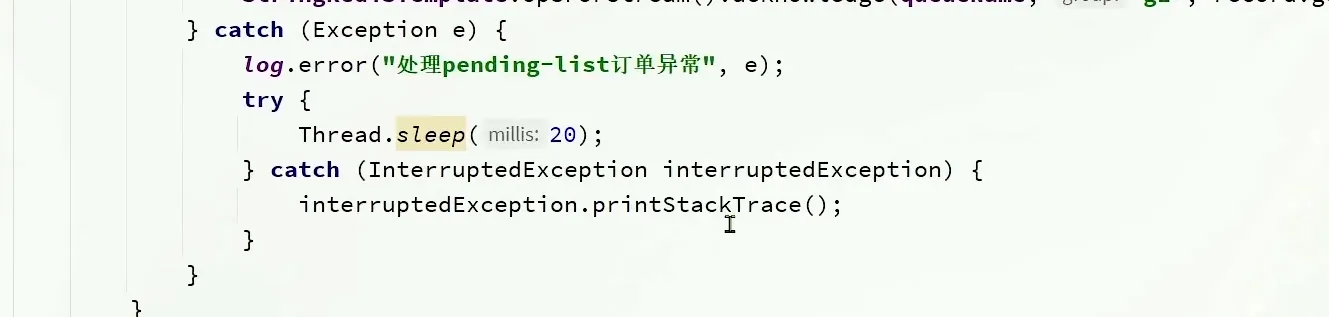
如果消息抛出异常, 我们就需要使用下面这个方法
其他常用数据结构
BitMap
实战场景:
在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
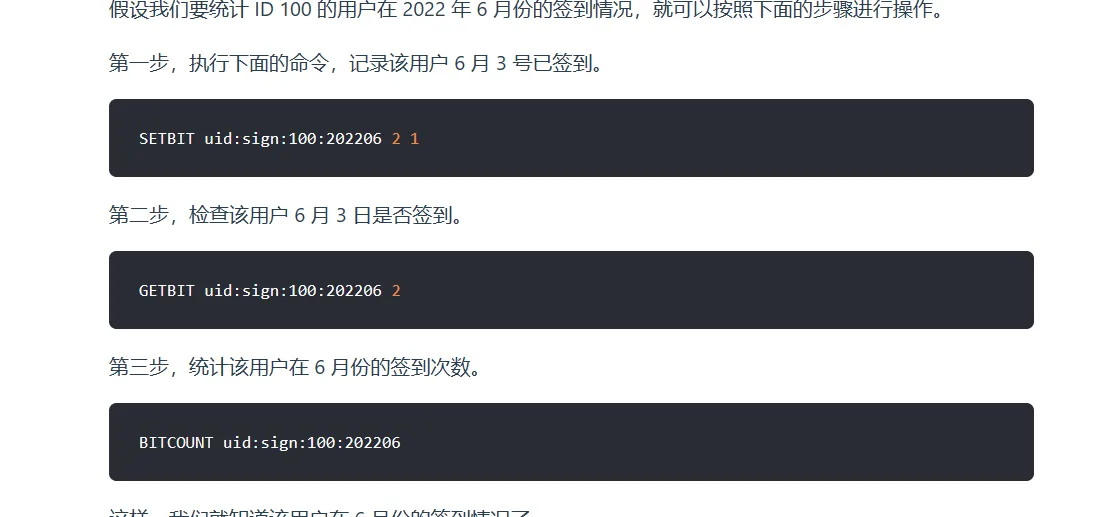
语法 key offset value(value只能是0 ~ 1)
如何统计本月首次打卡的时间,
BITPOS key bitValue [start] [end]判断用户的登录状态

统计连续打卡的日期
具体参考小林coding, 实现原理就是用AND与运算

HyperLogLog
在redis2.8.9中新增添的数据结构
提供不精确的重复计数
常见指令
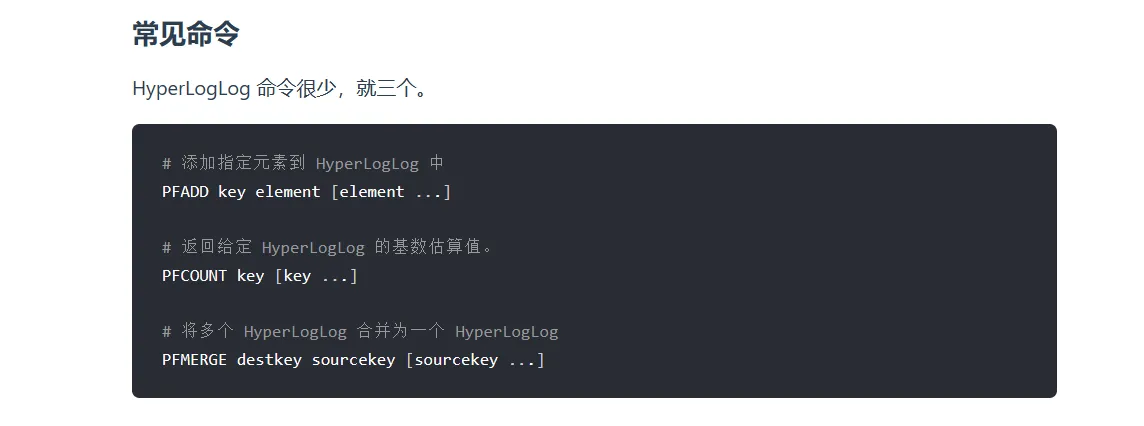
- 用来统计不重复的的元素个数
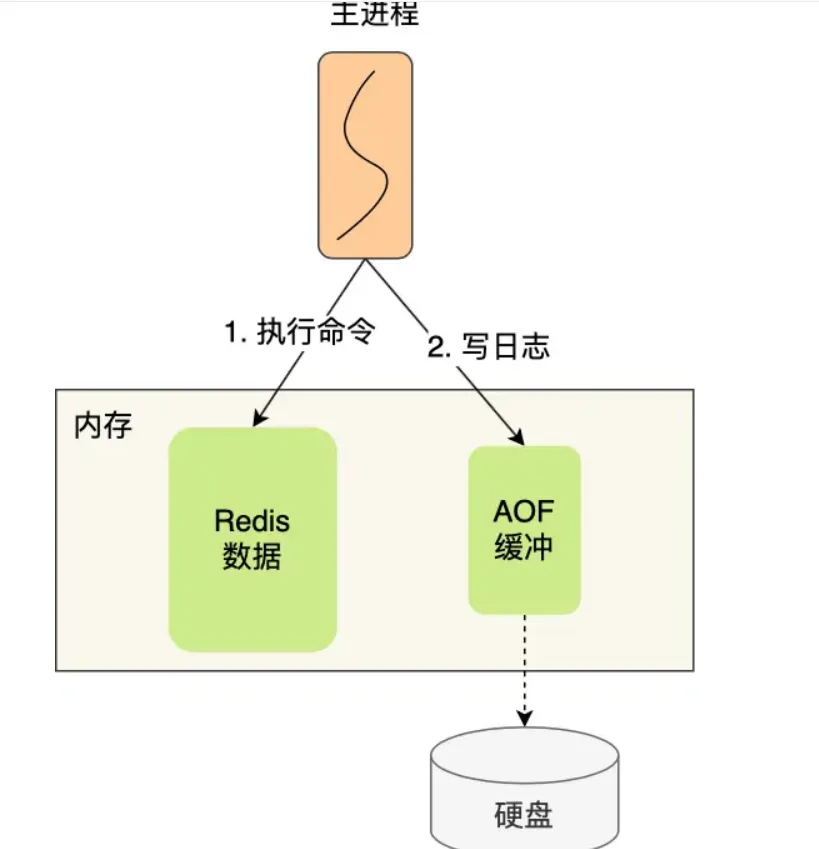
持久化
AOF
默认不会开启这个功能, 我需要到配置文件里面,给appendonly 从false 修改为 yes

先执行操作再写入
- 好处:
- 避免额外的检测开销
- 不会阻塞当前写操作命令的执行
- 坏处:
- 数据可能回丢失
- 阻塞下一个命令的执行
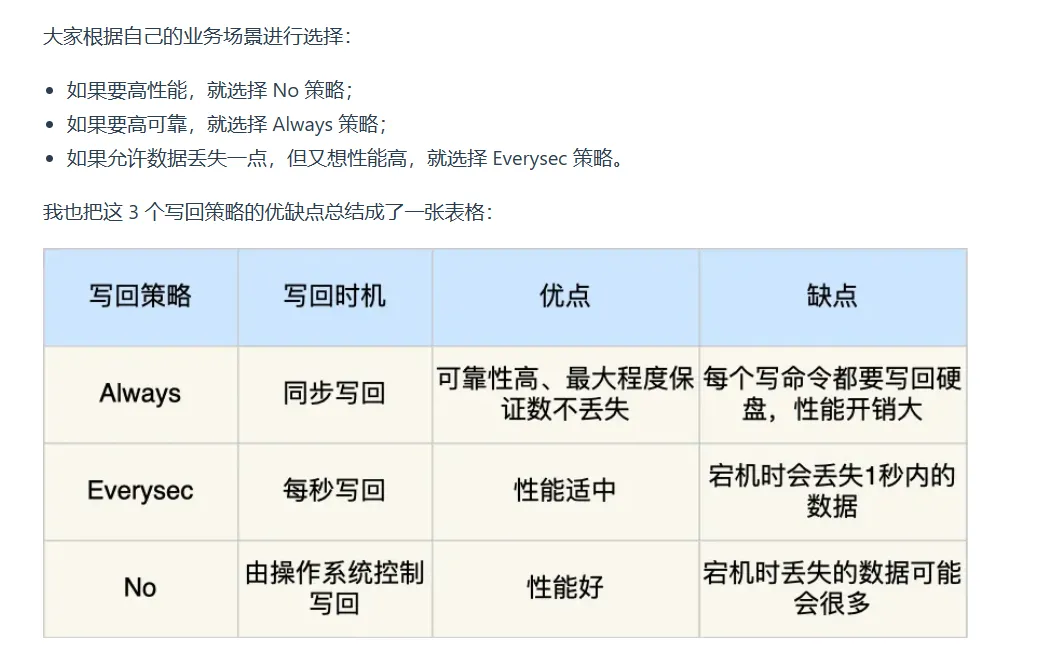
写入策略

需要根据业务来分析写入的方式
重写机制
- 默认, 选择最新的键值对存入。
- 再重写过程中是先写入到一个新的AOF文件里面, 然后用AOF文件去替代旧版的AOF
后台重写机制
Redis的重写AOF过程是由后台子进程bgrewriteaof完成的。(注意这里是子进程, 而不是线程,线程会共享内存地址, 那么就需要通过加锁来区分,更加影响速度了)
子进程会得到一个数据副本, 那这个副本是如何得到的呢?

当写入数据的时候会发送如下的操作


- 创建子进程的时候要复制页表等数据结构,需要消耗时间
- 触发写时复制的时候, 拷贝物理内存,也会造成阻塞

RDB
- RDB是某一个时刻redis的快照。 所以恢复数据的效率要高于AOF

生成方式
- save 命令就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- bgsave 命令会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞

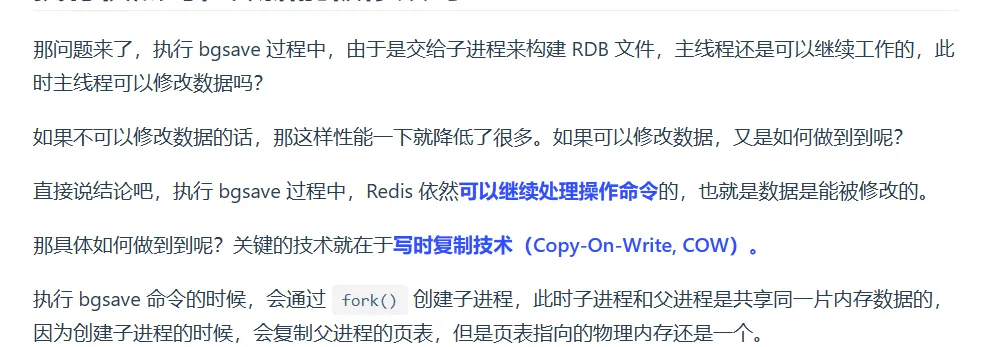
- 注意主线程, 操作的是操作之后复制产生数据副本, 而RDB操作的是操作之前的数据


混合持久化
- 将RDB 和 AOF 结合
1 | aof-use-rdb-preamble yes |
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
面经
大key值对redis的影响
如果是AOF日志的话, 那么分为下面三个情况进行分析

对于AOF重写和RDB的影响
- fork 耗时过长的解决方法


删除大key的时候, 不要使用del命令去删除, 而是使用unlink命令去删除, 因为unlink命令是异步删除
Redis过期淘汰删除策略内存淘汰策略
过期删除策略
设置过期时间

判断key是否过期
查看某一个指令的剩余生命周期, 使用ttl keyname
1 | typedef struct redisDb { |
- 过期字典的 key 是一个指针,指向某个键对象;
- 过期字典的 value 是一个 long long 类型的整数,这个整数保存了 key 的过期时间;
判定流程
字典实际上是哈希表,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找。当我们查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中:
- 如果不在,则正常读取键值;
- 如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该 key 已过期。
过期删除策略举例
- 定时删除;

- 惰性删除;

- 定期删除;

一般删除的策略
所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
惰性删除实现
1 | int expireIfNeeded(redisDb *db, robj *key) { |
Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据
lazyfree_lazy_expire参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 客户端; - 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
定期删除
1 | do { |
杂谈
测试高并发
JMeter 我们可以进行高并发的测试
设置过期时间
1 | stringRedisTemplate.opsForValue().set("login:code" + phone, code , 2, TimeUnit.MINUTES); |
小技巧
copyproperties
1 | //实体类的复制可以使用 |
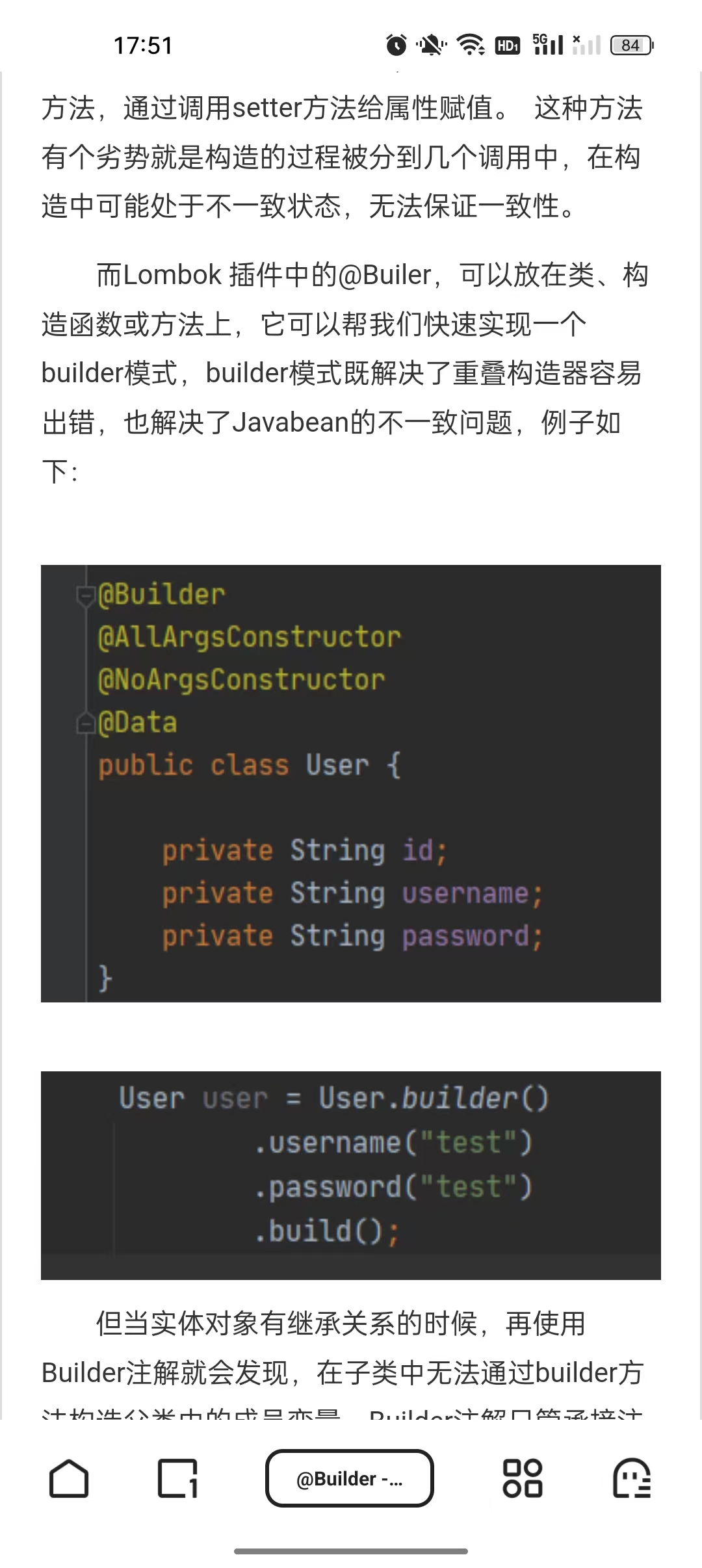
builder 注释
在实体类上加上@Builder
IDEA 的快捷键
ctrl + shift + u 将选中的代码变成大写
ctrl + shift + m 截取代码
前端的一些小知识

前端这里需要注意 在发送请求的时候,将所有的axios带入token请求
工具类
Collection
singleton

BeanUtil
fillBeanWithMap
将map对象转换到对应的类里面。 这个类是map对象散开的类型