资料获取
https://pan.baidu.com/s/1zRmwSvSvoDkWh0-MynwERA&pwd=1234
下载之后,点击实用篇 ,学习资料 , 然后点击day5, 在点击资料
基础认识
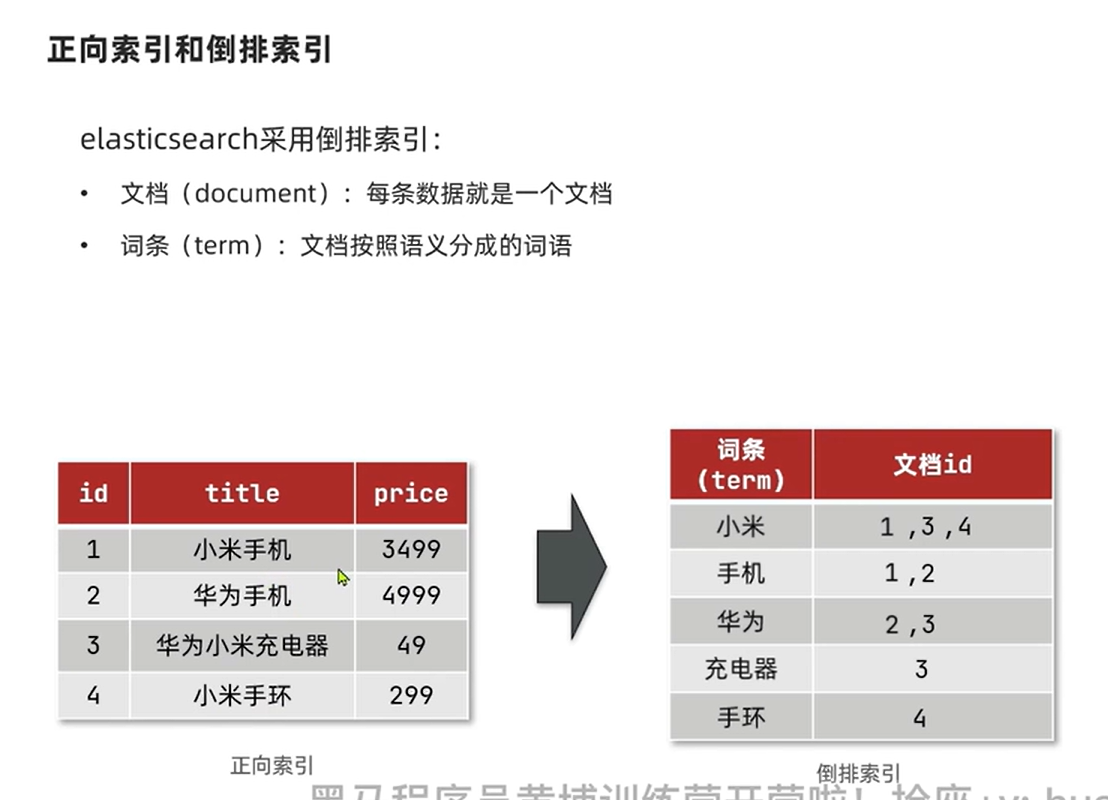
先分成根据关键词分成多个词条, 然后根据词条来搜索。
初始elasticsearch
文档
一个数据就是文档
所有的文档数据都会被序列化转换为json格式,然后存储到elasticsearch中
索引
相同类型文档的集合
比如会被分成 商品索引, 用户索引, 订单索引
- mapping: 索引中文档的字段约束信息, 类似于表的结构约束
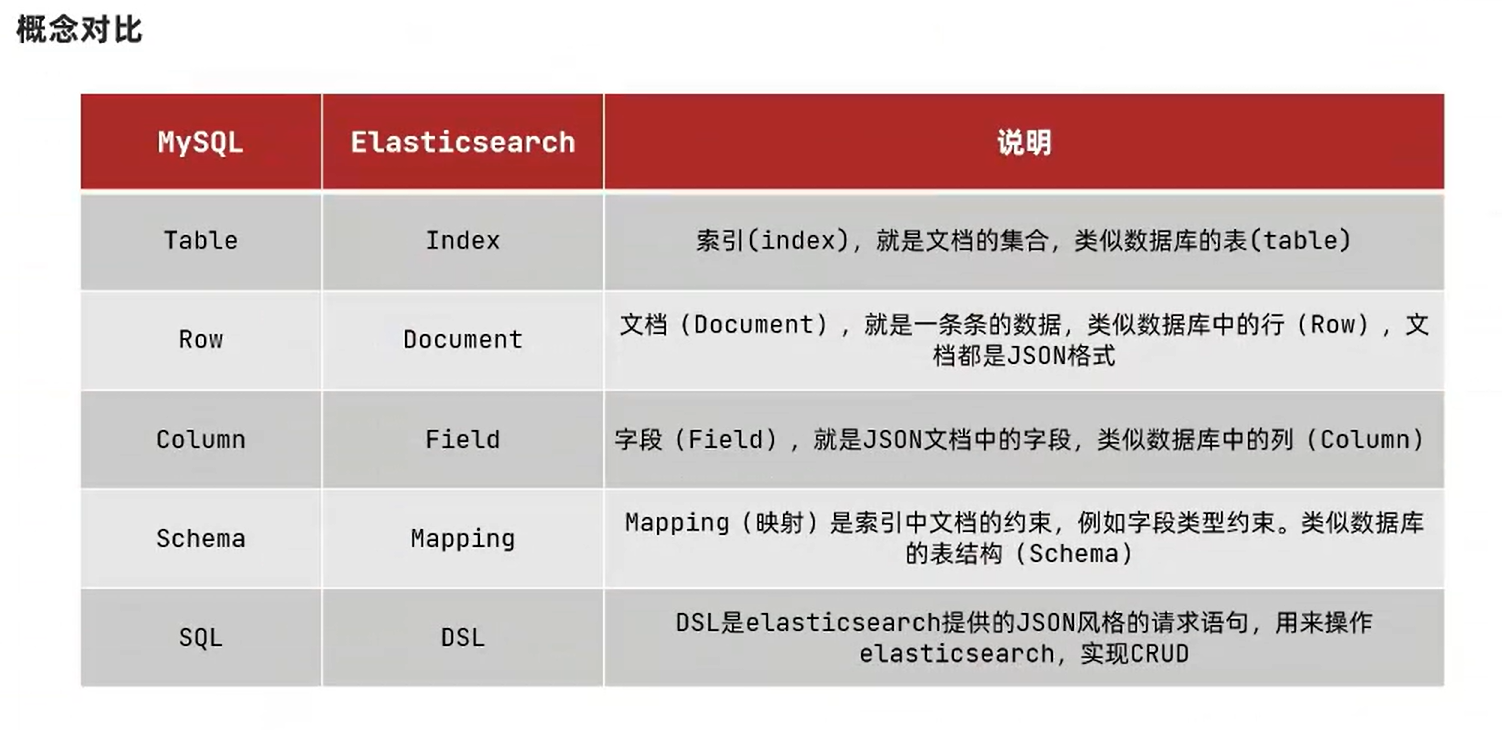
mysql 和 es的区别
概念
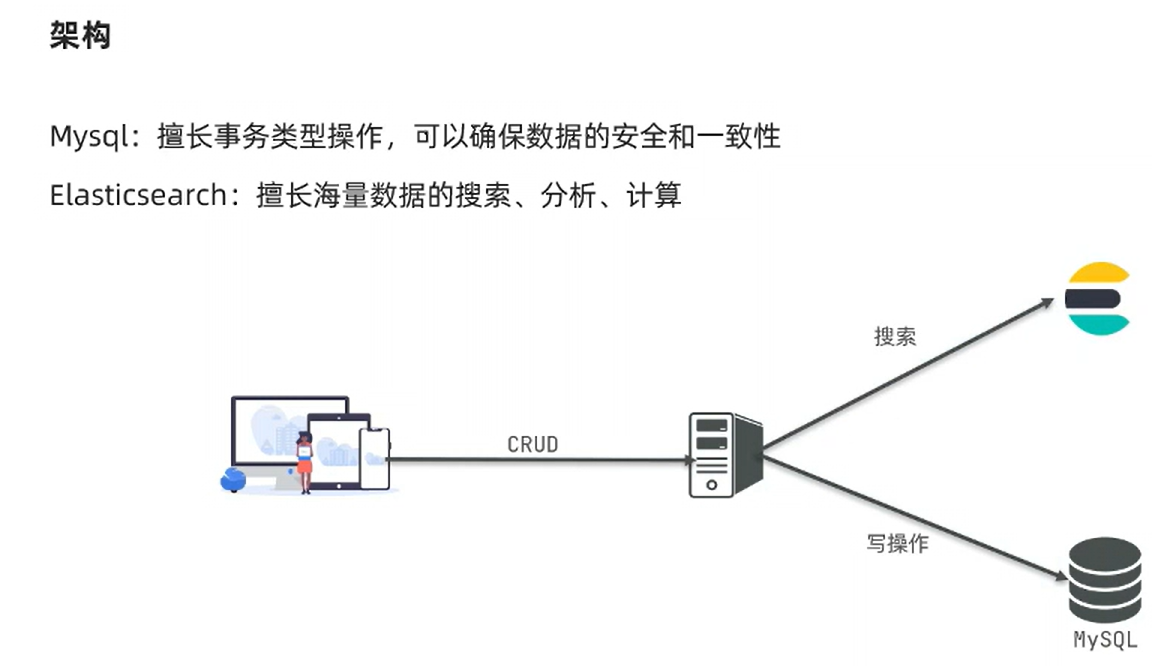
架构
安装es
单点部署
创建网络
1
| docker network create es-net
|
拉取镜像
1
| docker pull elastinsearch:7.12.1
|
运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
|
测试
然后在浏览器里面打开ip地址加上9200 端口号
就会获得类似于这样的json格式数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| {
"name": "36a24428b8c9",
"cluster_name": "docker-cluster",
"cluster_uuid": "z2BSZzopTJ6l9An61d0TMw",
"version": {
"number": "7.12.1",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "3186837139b9c6b6d23c3200870651f10d3343b7",
"build_date": "2021-04-20T20:56:39.040728659Z",
"build_snapshot": false,
"lucene_version": "8.8.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
|
安装kibana
- 需要注意的是, 要和你的es 在同一个网络环境, 在同一个网络, 可以通过容器名称来互联
通过这个可以可视化es ,便于学习
安装
1
2
|
docker pull kibana:7.12.1
|
运行
1
2
3
4
5
6
7
8
9
| docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
docker logs -f kibana
|
测试
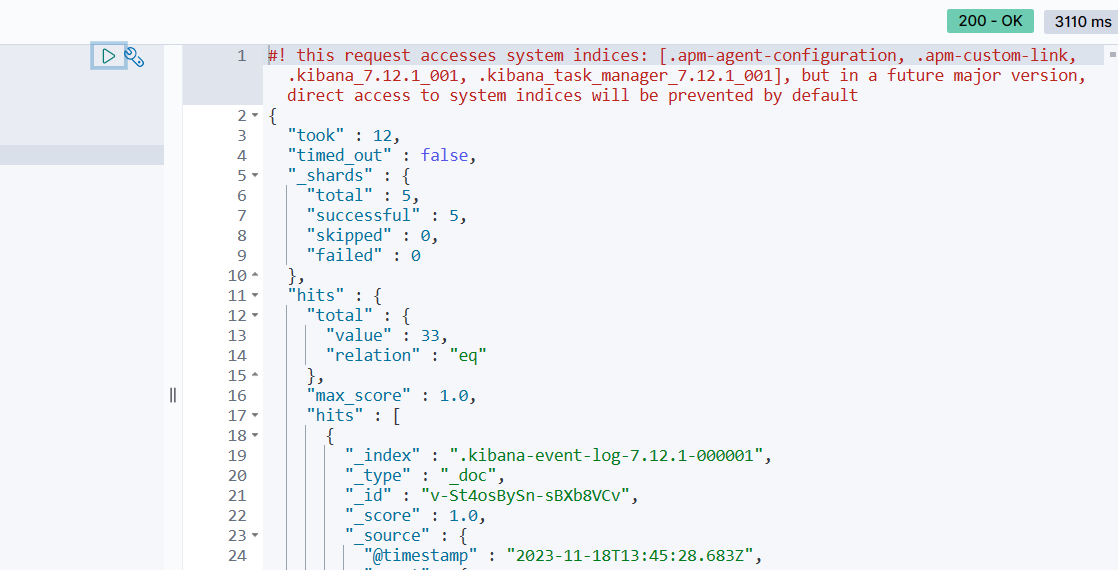
GET /
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {
"name" : "36a24428b8c9",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "z2BSZzopTJ6l9An61d0TMw",
"version" : {
"number" : "7.12.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "3186837139b9c6b6d23c3200870651f10d3343b7",
"build_date" : "2021-04-20T20:56:39.040728659Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
|
分词器

1
2
3
4
5
| POST /_analyze
{
"analyzer": "standard",
"text": "黑马程序员学习java太棒了!"
}
|
如果你选择english/standard 的时候,他会按照一个字符一个字符来分

使用专门的中文分词器 - IK
在线安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
docker exec -it es /bin/bash
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
./bin/elasticsearch-plugin install https://github.com.cnpmjs.org/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
exit
docker restart elasticsearch
|
离线安装
1
| docker volume inspect es-plugins
|
测试
打开刚刚的浏览器
1
2
3
4
5
6
7
8
9
10
11
12
| POST /_analyze
{
"analyzer": "ik_smart",
"text": "黑马程序员学习java太棒了!"
}
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员学习java太棒了!"
}
|
这个时候分词的结果就是正常的

操作
索引操作
mapping映射属性
type: 字段数据类型,
字符串: text(可分词的文本),keyword(精确值,不可以分词的文本)
如下图,邮箱就是keyword, 名字就是text

数值: long,integer, short,byte,double,float
布尔: boolean
日期:date
index: 是否创建倒排索引, 默认是true
analyzer: 使用哪种分词器
properties: 该字段使用的子字段
索引库CRUD
创建索引库名

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| PUT /heima
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword",
"index": false
},
"name" :{
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
|
然后生成了下面的结果
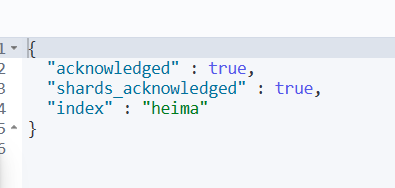
删除和 查看索引
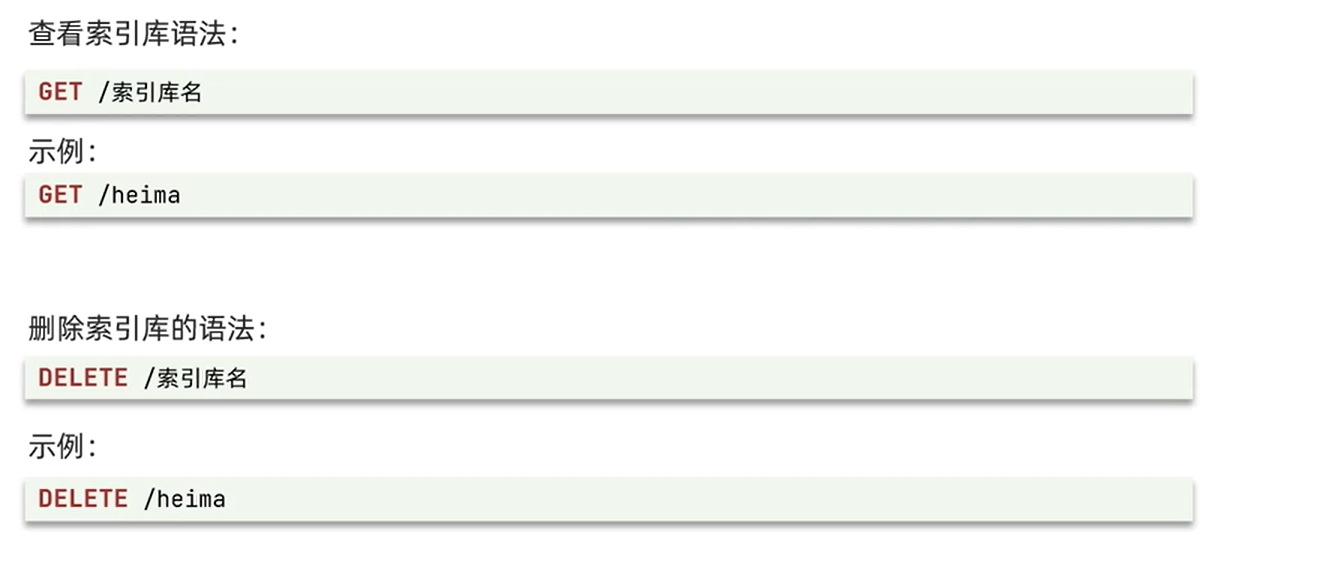
修改索引库
在es中禁止修改修改索引库
但是我们可以添加新的字段
1
2
3
4
5
6
7
8
| PUT /index_name/_mapping
{
"properties": {
"new_index":{
"type": "integer"
}
}
}
|
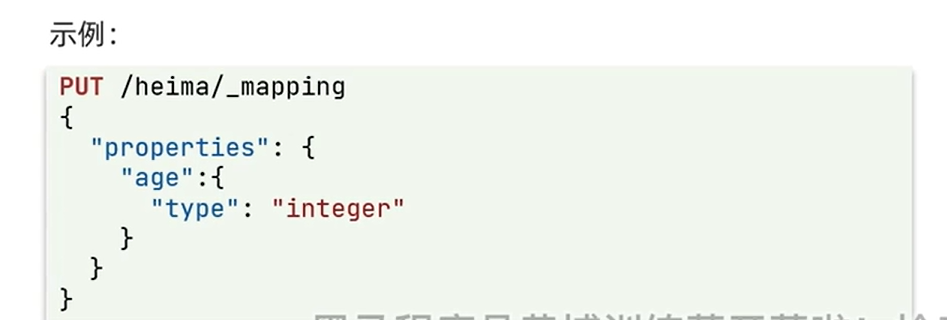
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
GET /heima
|
发现增添了 age

文档操作
文档的CRUD
添加文档

1
2
3
4
5
6
7
8
9
10
|
POST /heima/_doc/1
{
"info": "黑马程序员java讲师",
"email": "114514@tomcat.cn",
"name": {
"firstname": "alan",
"lastname": "yaeer"
}
}
|
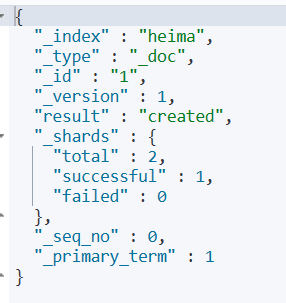
查询文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "黑马程序员java讲师",
"email" : "114514@tomcat.cn",
"name" : {
"firstname" : "alan",
"lastname" : "yaeer"
}
}
}
|
删除文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| {
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
|
修改文档
全量修改
1
2
3
4
5
6
7
8
9
| PUT /heima/_doc/1
{
"info": "黑马程序员java讲师",
"email": "11451@QQ.COM",
"name": {
"firstName": "云",
"lastname" : "赵"
}
}
|
增量修改
1
2
3
4
5
6
| POST /heima/_update/1
{
"doc": {
"email": "ZYun@itcast.cn"
}
}
|
RESTClient 操作索引库(java)
案例


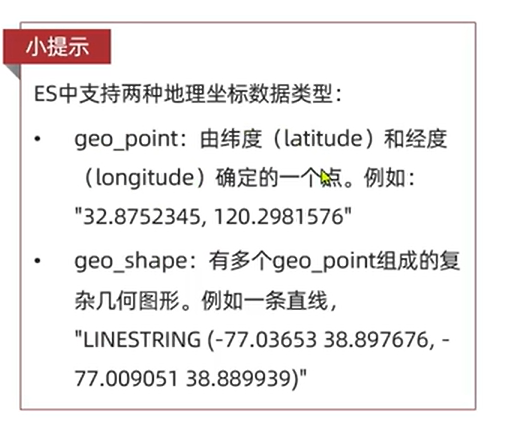
1
2
3
| "location": {
"type": "geo_point"
}
|
- 字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段
在你需要添加的合并字段添加一个copy_to 为all
(这样可以实现, 多个字段同时搜索)
先设置一个字段
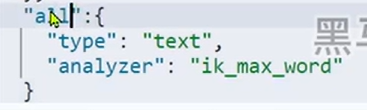
然后, 在所有的字段都加上一个all
初始化javaRestClient
依赖引入
1
2
3
4
5
| <dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
|
1
2
3
| <properties>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
|
添加一个测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class HotelIndexTest {
private RestHighLevelClient client;
@Test
void testInit() {
System.out.println(client);
}
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://118.25.143.28:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
|
创建索引
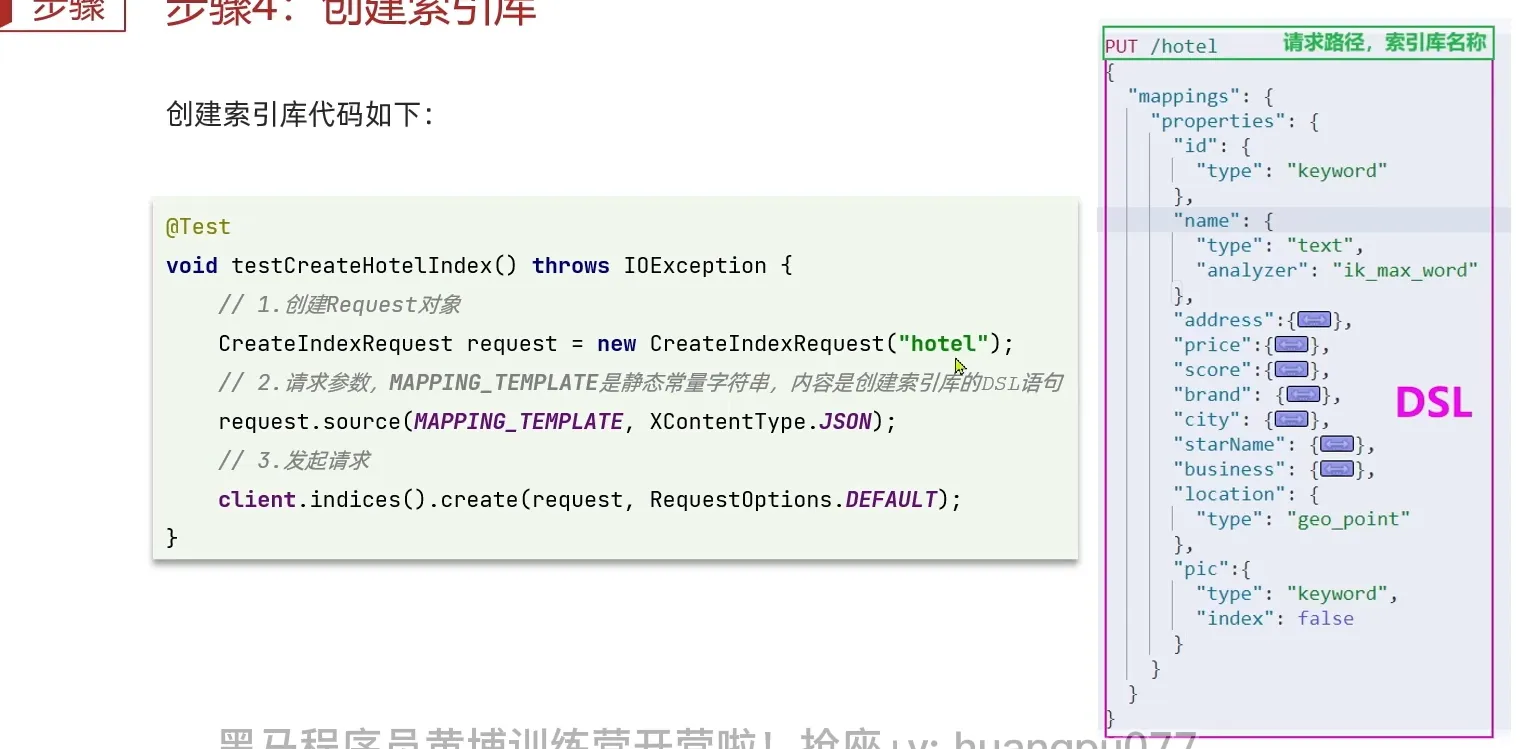
复制json的时候, 首行, 不需要被复制
如果代码跑起来报错, 可以查看你导入的包, 是不是正确的
应该是下面这个才对
1
| import org.elasticsearch.client.indices.CreateIndexRequest;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| {
"hotel" : {
"aliases" : { },
"mappings" : {
"properties" : {
"address" : {
"type" : "keyword",
"index" : false
},
"all" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"brand" : {
"type" : "keyword"
},
"business" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"location" : {
"type" : "geo_point"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"pic" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "integer"
},
"score" : {
"type" : "integer"
},
"starName" : {
"type" : "keyword"
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "hotel",
"creation_date" : "1700828818690",
"number_of_replicas" : "1",
"uuid" : "hJ5Hsr9iQbCwOtq-OnPuew",
"version" : {
"created" : "7120199"
}
}
}
}
}
|
删除索引库, 判断索引库是否存在
1
2
3
4
5
6
7
8
9
| @Test
void testDeleteHotelIndex () throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request, RequestOptions.DEFAULT);
}
|
1
2
3
4
5
6
7
8
| @Test
void testExistHotelIndex () throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists ? "存在": "不存在");
}
|

RestCient操作文档(java)
创建文档
我们的内容


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| @Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
@Test
void testInit() {
System.out.println(client);
}
@Test
void testAddDocument () throws IOException {
Hotel hotel = hotelService.getById(61083L);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://localhost:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
|

查询文档

1
2
3
4
5
6
7
8
9
10
| @Test
void testGetDocumentById() throws IOException {
GetRequest request = new GetRequest("hotel", "61083");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
|
更新文档
同创建文档

1
2
3
4
5
6
7
8
9
10
11
| @Test
void testUpdateDocument () throws IOException {
UpdateRequest request = new UpdateRequest("hotel", "61083");
request.doc(
"price", "952",
"starName", "四钻"
);
client.update(request, RequestOptions.DEFAULT);
}
|
删除文档
1
2
3
4
5
| @Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("hotel", "61083");
client.delete(request, RequestOptions.DEFAULT);
}
|

批量导入索引库
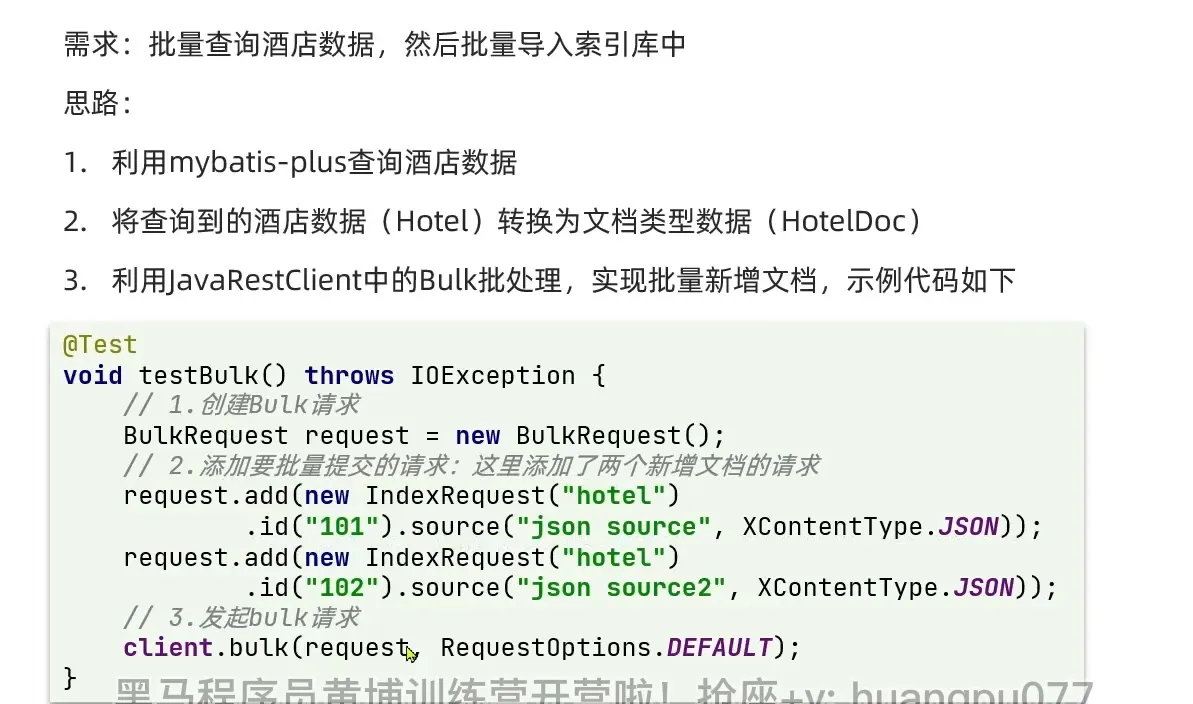
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Test
void testBulkRequest() throws IOException {
List<Hotel> hotels = hotelService.list();
BulkRequest request = new BulkRequest();
for(Hotel hotel: hotels){
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel").
id(hotelDoc.getId().toString()).
source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
client.bulk(request, RequestOptions.DEFAULT);
}
|
批量查询的 dsl 语法
GET /index名/_search
分布式搜索索引
DSL查询语法(简单查询)
查询所有, match_all

1
2
3
4
5
6
7
8
9
| GET /hotel/_search
{
"query":
{
"match_all":{
}
}
}
|
- 全文检索查询: 利用分词器对用户输入内容分词, 然后去倒排索引库里面去匹配
- match_query
- multi_match_query
- 精确查询:根据精确词条查询数据,一般是查找keyword、数值、日期、boolean等类型字段
- 地理查询: 根据经纬度进行查询
- geo_distance
- geo_bounding_box
- 复合查询:复合查询可以将上诉各种查询条件组合起来,合并查询
match查询
1
2
3
4
5
6
7
8
| GET /hotel/_search
{
"query": {
"match":{
"all": "外滩如家"
}
}
}
|
1
2
3
4
5
6
7
8
9
| GET /hotel/_search
{
"query": {
"multi_match":{
"query": "外滩如家",
"fields": ["brand", "name", "business"]
}
}
}
|
精确查询
1
2
3
4
5
6
7
8
9
10
| GET /hotel/_search
{
"query":{
"term":{
"city":{
"value":"上海"
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
GET /hotel/_search
{
"query": {
"range":{
"price":{
"gte": 100,
"lte": 300
}
}
}
}
|
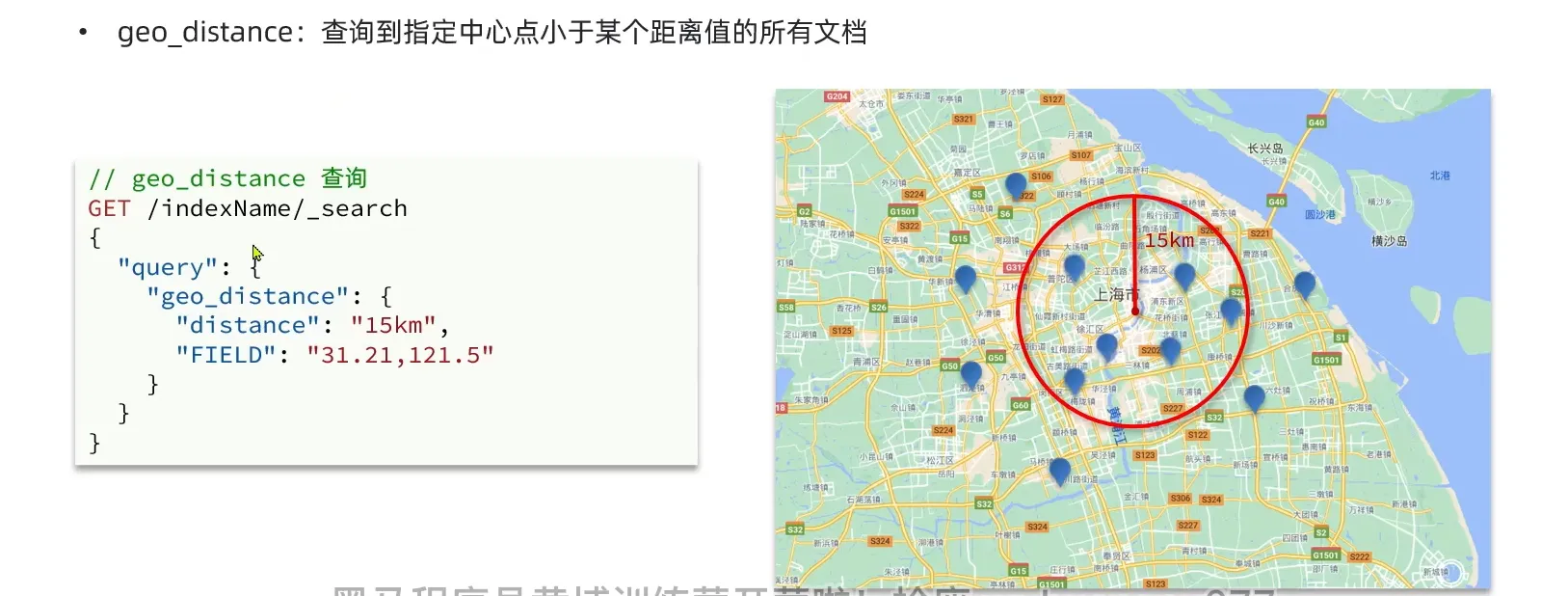
地理查询
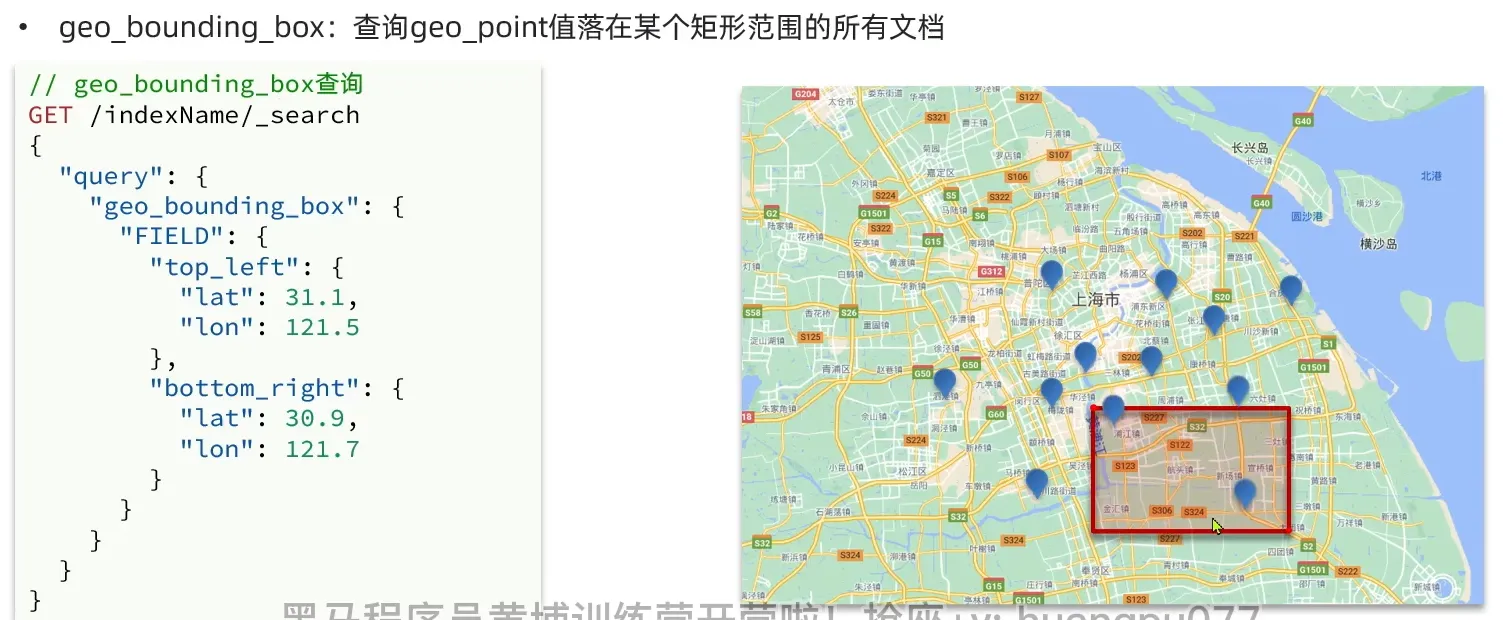
- geo_distance 查询到指定中心点小于某个距离值的文档
1
2
3
4
5
6
7
8
9
| GET /hotel/_search
{
"query": {
"geo_distance":{
"distance": "15km",
"location": "31.21, 121.5"
}
}
}
|
复合查询

- 但是上面这种算法现在被废弃了, 我们使用了BM25算法
它的优越性
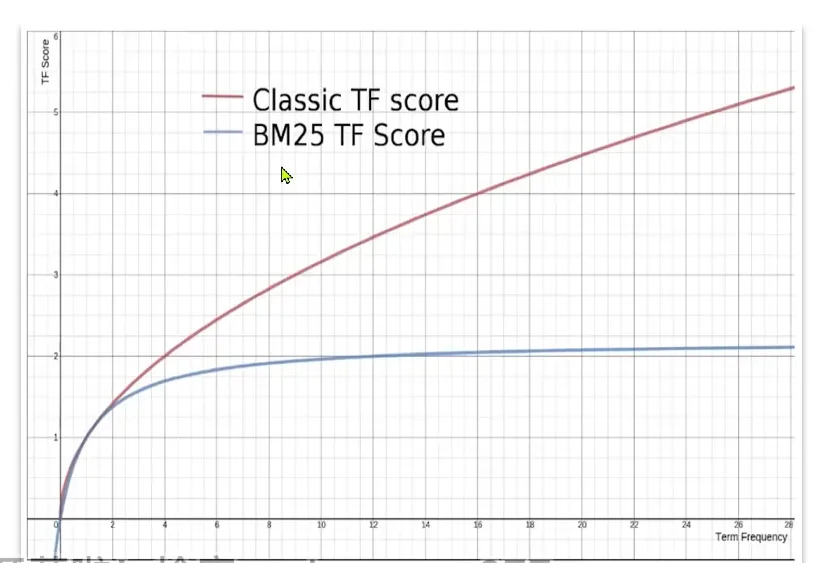

Function Scrore query
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
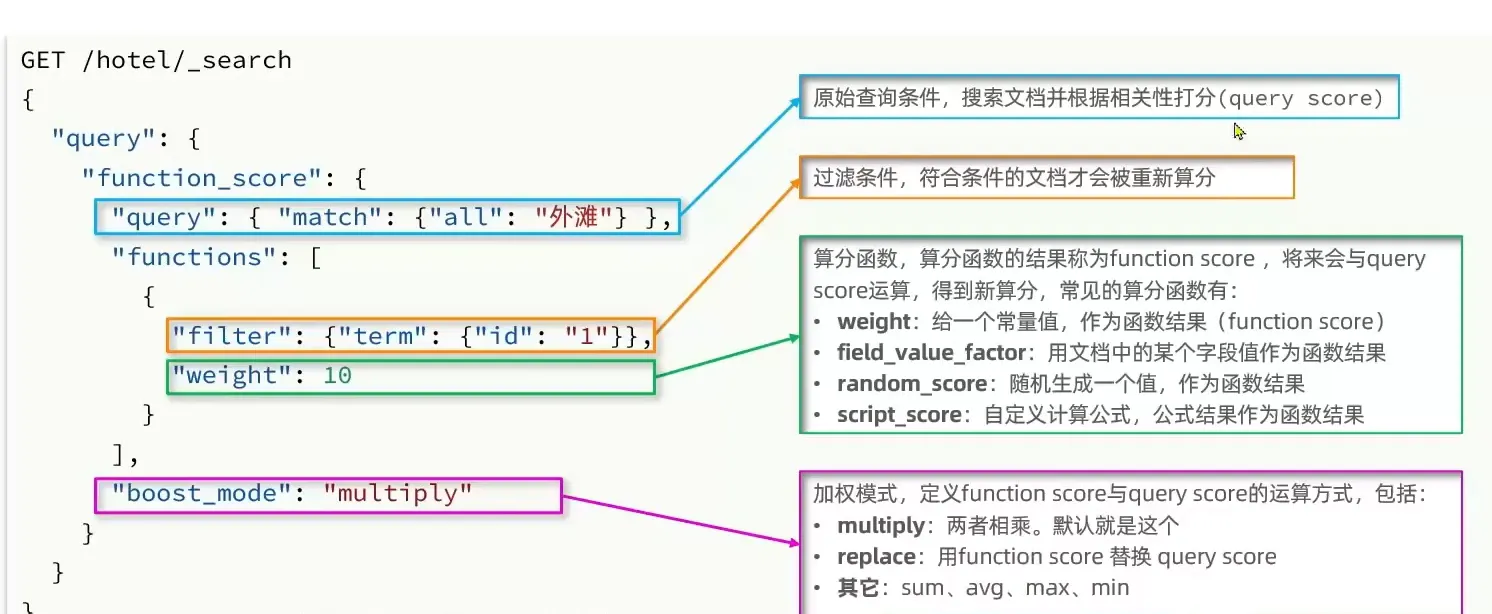
| GET /hotel/_search
{
"query":{
"function_score":{
"query": {"match": {"all": "外滩"}},
"functions": [
{
"filter": {"term": {"id": "1"}},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Get /hotel/_search
{
"query": {
"function_score":{
"query": {"match": {
"all" : "外滩"
}},
"function": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight" : 10
}
],
"boost_mode": "sum"
}
}
}
|

boolean Query(复合查询)
- 需要注意must 放入的条件会参与算法, 但是 filter不会

must 参与打分, filter不参与打分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| GET /hotel/_search
{
"query": {
"bool": {
"must": {
"match": {
"name": "如家"
}
},
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
|
排序

1
2
3
4
5
6
7
8
9
10
11
| GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc"
}
]
}
|
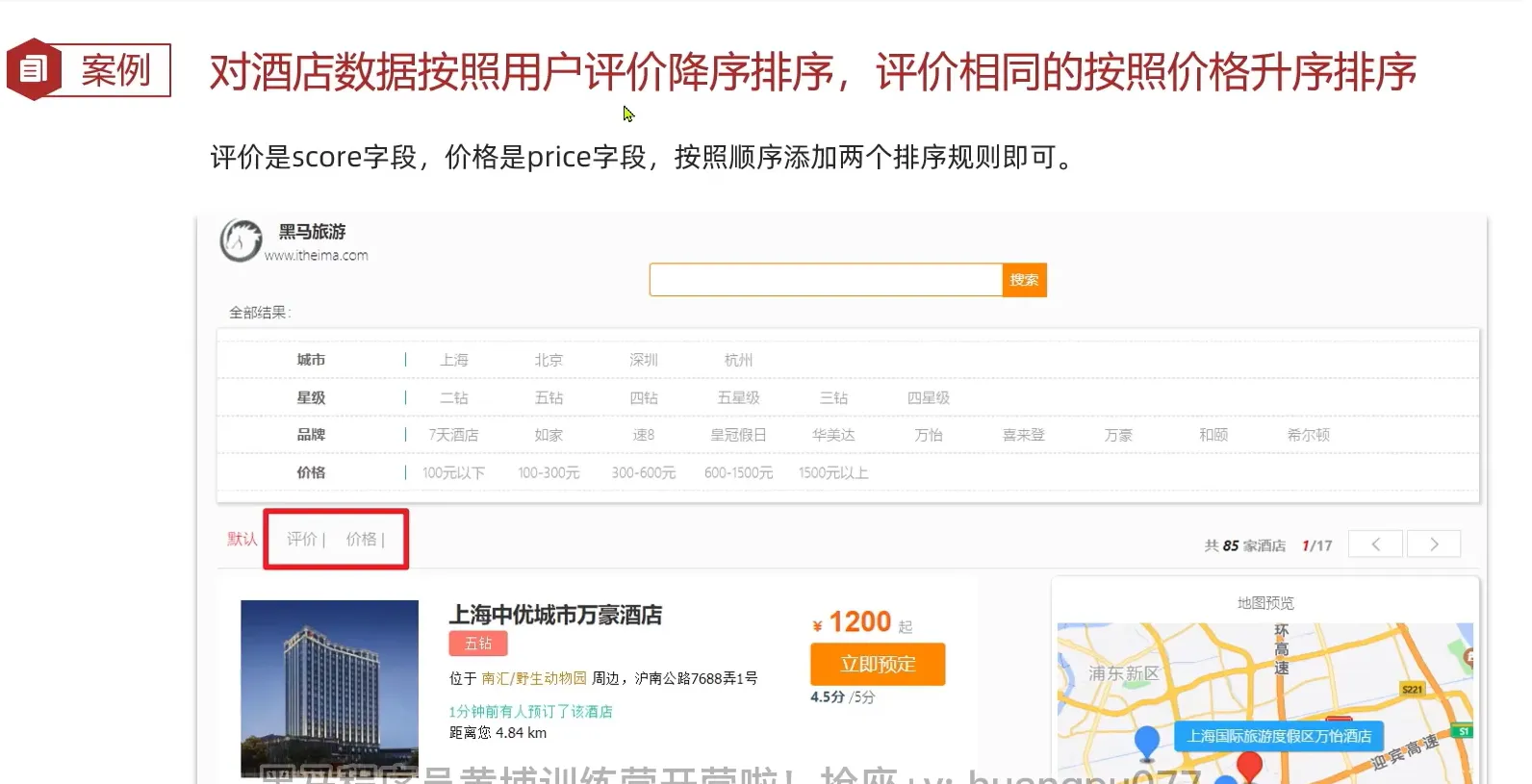
案例1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}
|
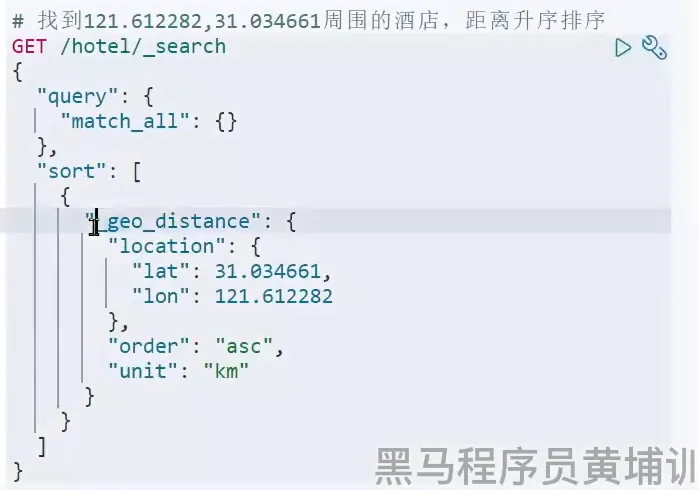
地理字段的排序
分页
elastci 默认的分页参数是10个, 所以你每次查询都只能查到前10个

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 10
}
|
- 如果要查询990 ~ 1000 的时候, 查询的过程就是(这是因为他数据结构的特殊决定的)
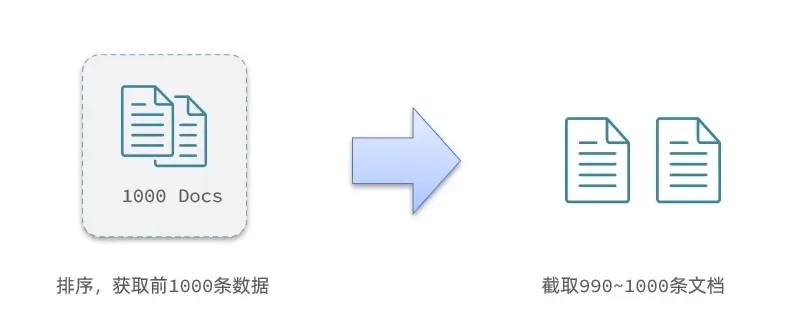
但是如果是集群的时候,这就会有大麻烦。 因为每一个分片都必须返回前1000个数据,然后把这些数据何在一起, 然后排序。
并且单次查询的个数,不能超过10000条。
这是他的解决方法
但是search after不支持随机查询。
scroll 对内存的消耗过大

高亮
就是把所有的搜索结果的关键字突出显示出来
就是通过添加标签

那么这个标签是谁家的呢?

- 注意点: 高亮查询, 搜索字段, 和高亮字段必须一致(但是可以添加配置项)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
|
RestClient 操作搜索(java)
查询
match_all
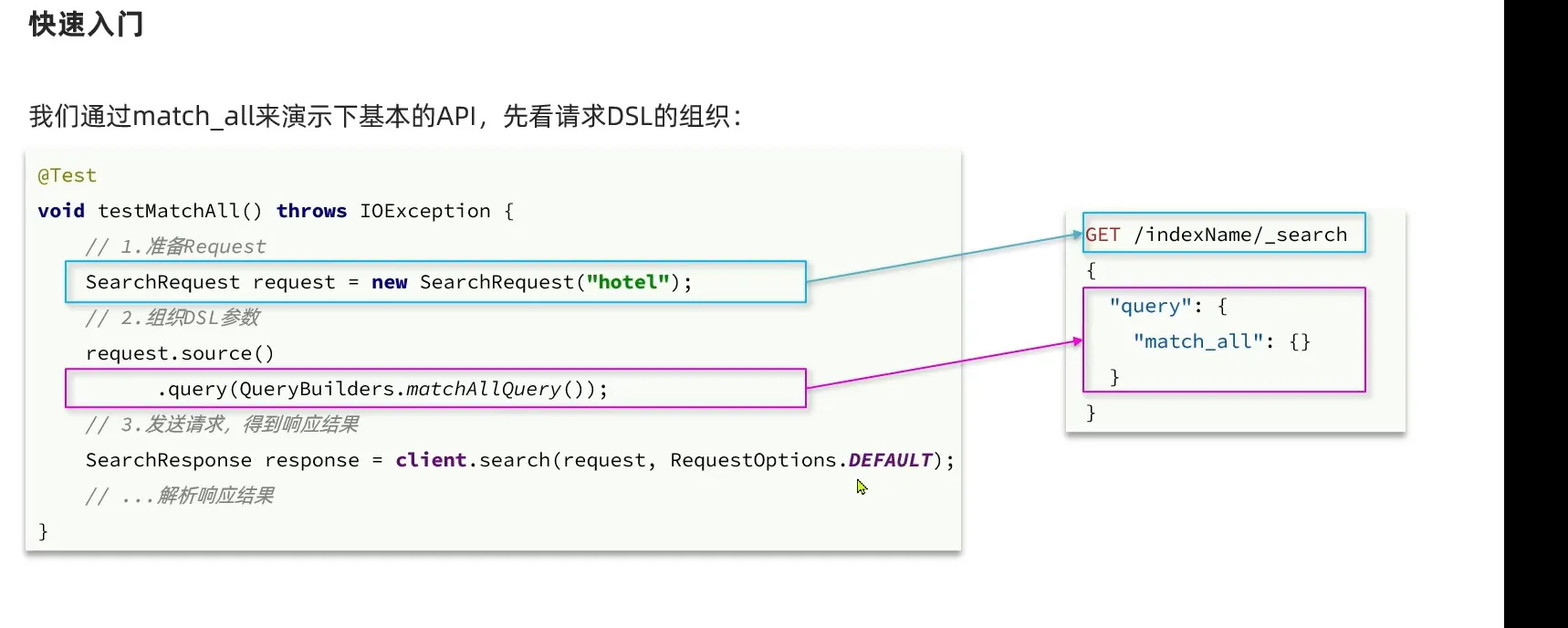
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
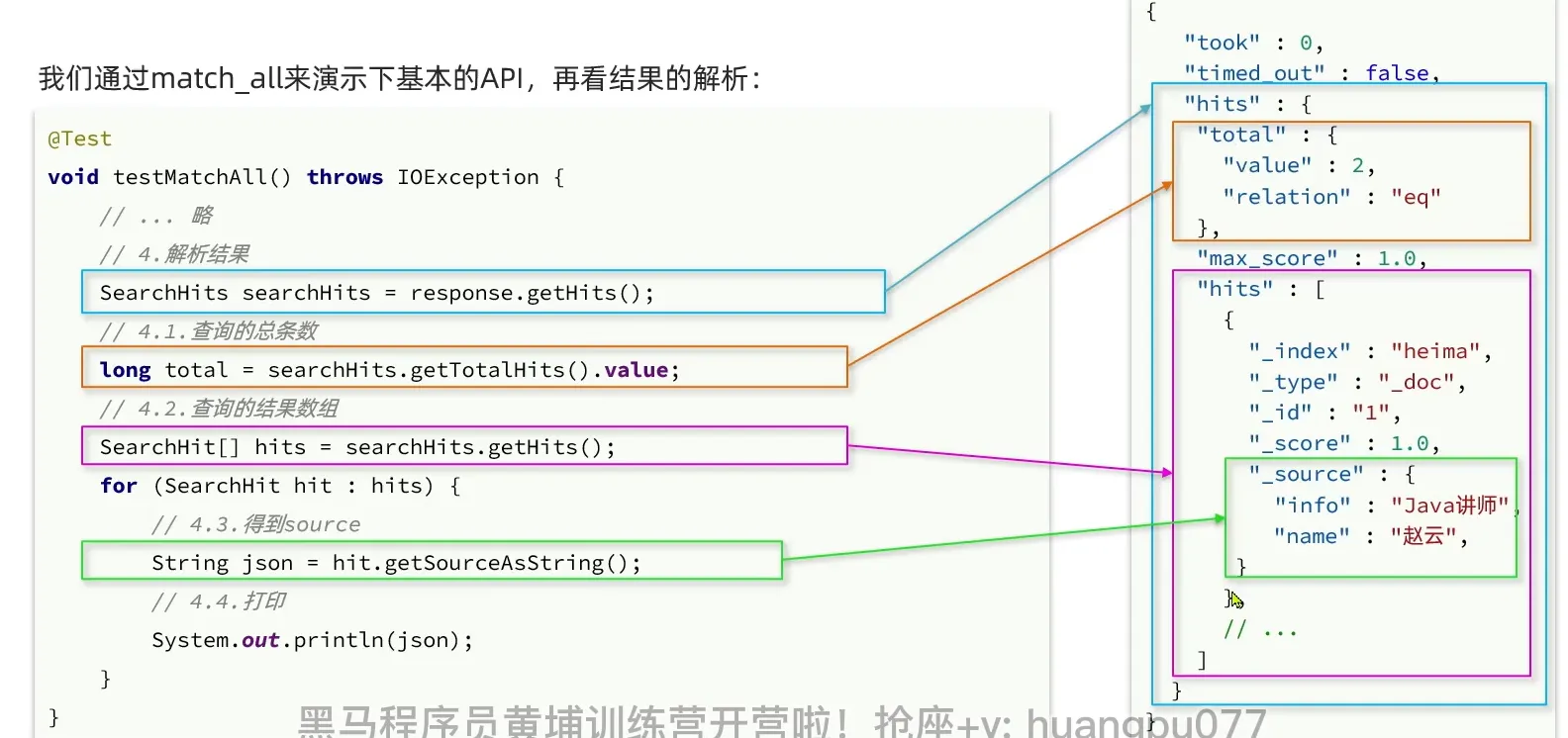
| @Test
void testMatchAll () throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
Long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total +"条数据");
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits){
String json = hit.getSourceAsString();
JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + json);
}
}
|
解析response

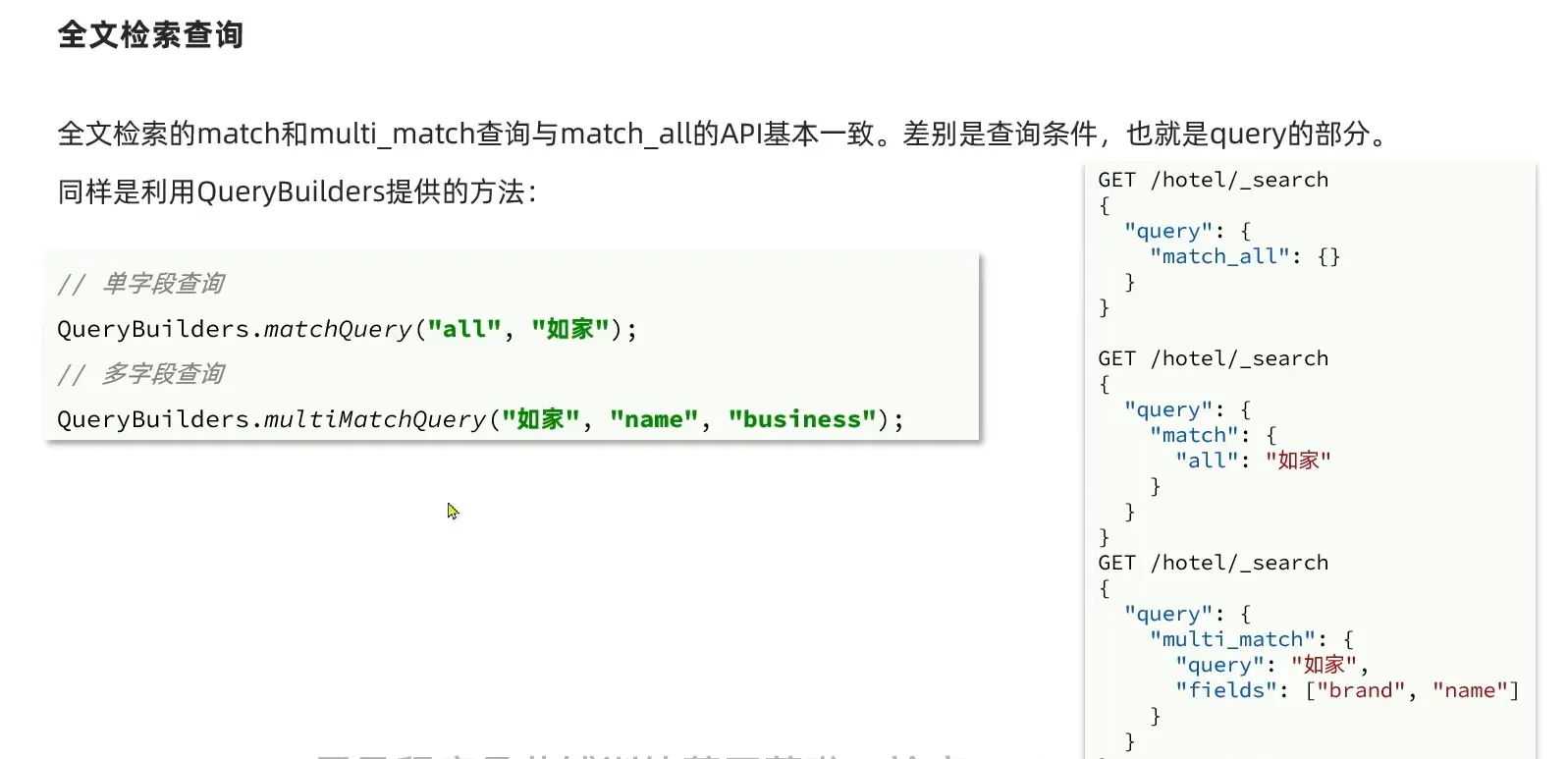
match & multi_match
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Test
void testMatch() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all", "如家"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
Long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total +"条数据");
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits){
String json = hit.getSourceAsString();
JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + json);
}
}
|
term & range

boolean

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
void testBoolean() throws IOException {
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
|
排序 & 分页

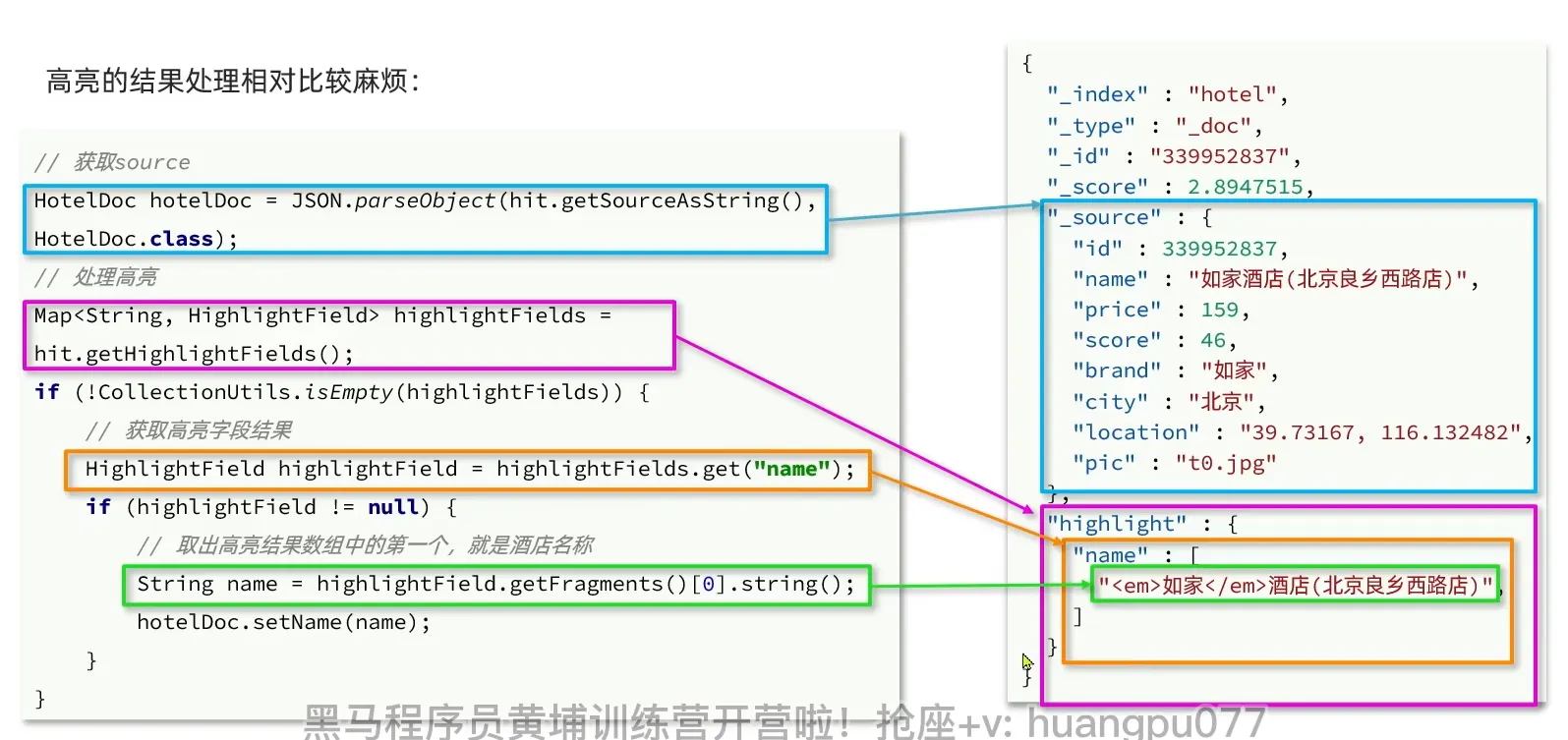
高亮

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Test
void testHighlight() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all", "如家"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
request.source();
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
|
黑马旅游(案例)
localhost:8089打开页面
day1 代码
pojo
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
private String city;
private String brand;
private String starName;
private String minPrice;
private String maxPrice;
}
|
service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| @Autowired
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
String key = params.getKey();
BoolQueryBuilder boolQuery = buildBasicQuery(params, key);
request.source().query(boolQuery);
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static BoolQueryBuilder buildBasicQuery(RequestParams params, String key) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if(key == null || "".equals(key)){
boolQuery.must(QueryBuilders.matchAllQuery());
}
else{
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
if(params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
if(params.getMinPrice() != null && !params.getMinPrice().equals("")){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
if(params.getMaxPrice() != null && params.getMinPrice() != null){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
return boolQuery;
}
private PageResult handleResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
Long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total +"条数据");
SearchHit[] hits = searchHits.getHits();
List<HotelDoc> hotels = new ArrayList<>();
for(SearchHit hit: hits){
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
hotels.add(hotelDoc);
System.out.println("hotelDoc = " + hotelDoc );
}
return new PageResult(total, hotels);
}
|
controller
1
2
3
4
5
6
7
8
9
10
11
| @RestController
@RequestMapping("/hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
@PostMapping("/list")
public PageResult search(@RequestBody RequestParams params) {
return hotelService.search(params);
}
}
|
day2 代码

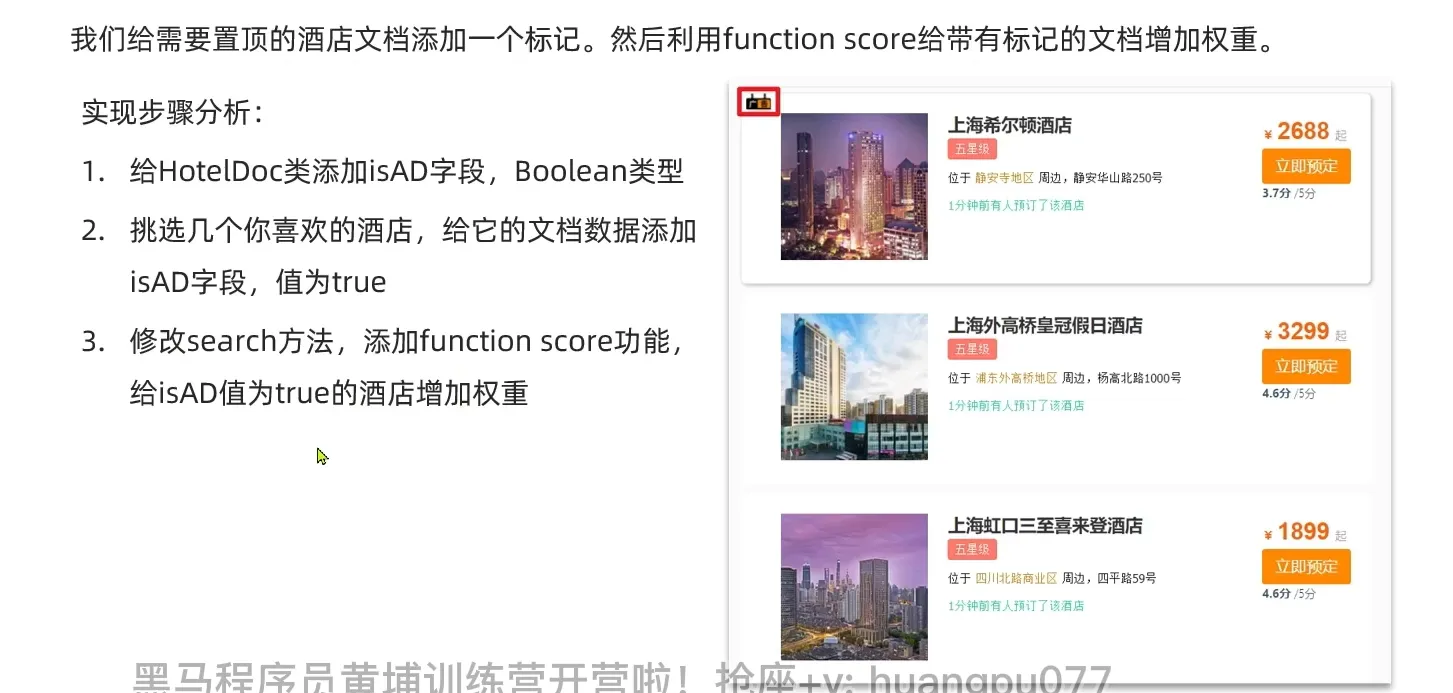
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| POST /hotel/_update/1902197537
{
"doc": {
"isAD": true
}
}
POST /hotel/_update/2056126831
{
"doc": {
"isAD": true
}
}
POST /hotel/_update/1989806195
{
"doc": {
"isAD": true
}
}
POST /hotel/_update/2056105938
{
"doc": {
"isAD": true
}
}
POST /hotel/_update/541619
{
"doc": {
"isAD": true
}
}
|
1
2
3
4
5
6
7
| if(location != null && location.equals("") == false){
request.source().sort(SortBuilders
.geoDistanceSort("location", new GeoPoint(location))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS));
}
|

1
2
3
4
5
6
7
| FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(boolQuery,
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD", true),
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
|
分布式索引
聚合

Bucket 聚合


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| GET /hotel/_search
{
"size": 0,
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}
|
Metrics 聚合

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs":{
"scoreAgg": {
"stats":{
"field": "score"
}
}
}
}
}
}
|
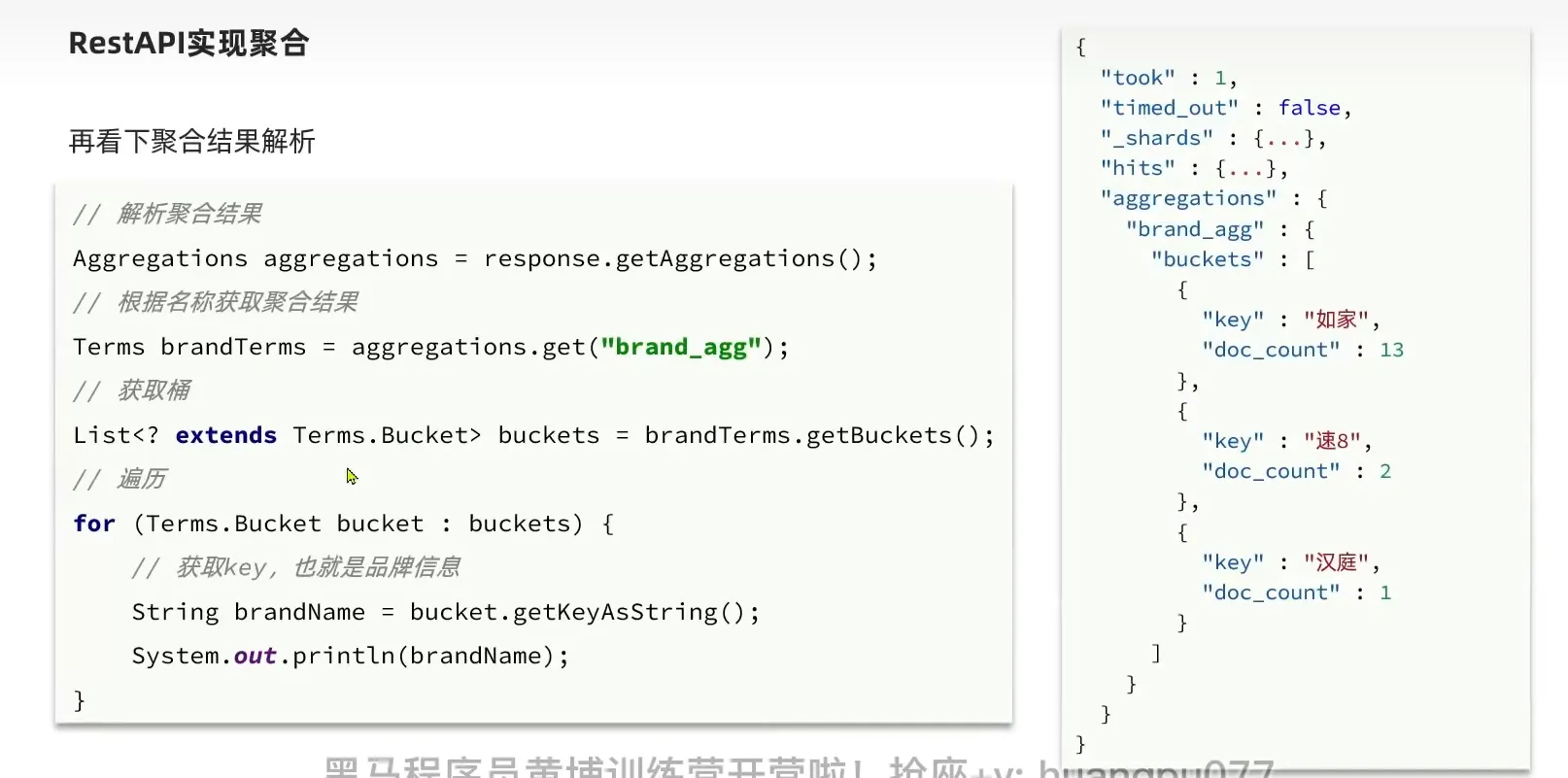
RestApi 聚合

1
2
3
4
5
6
7
8
9
10
11
12
13
| SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all", "如家"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
request.source();
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
|
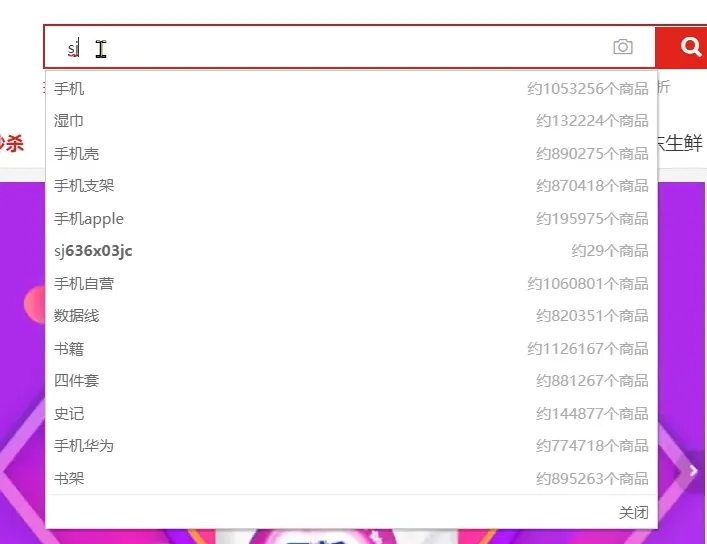
自动补全
输入一个sj 就会自动跳出来下面这个
拼音分词器
上传py 文件到 /var/lib/docker/volumes/es-plugins/_data
然后 docker restart es
1
2
3
4
5
| POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
|
改造拼音分词器
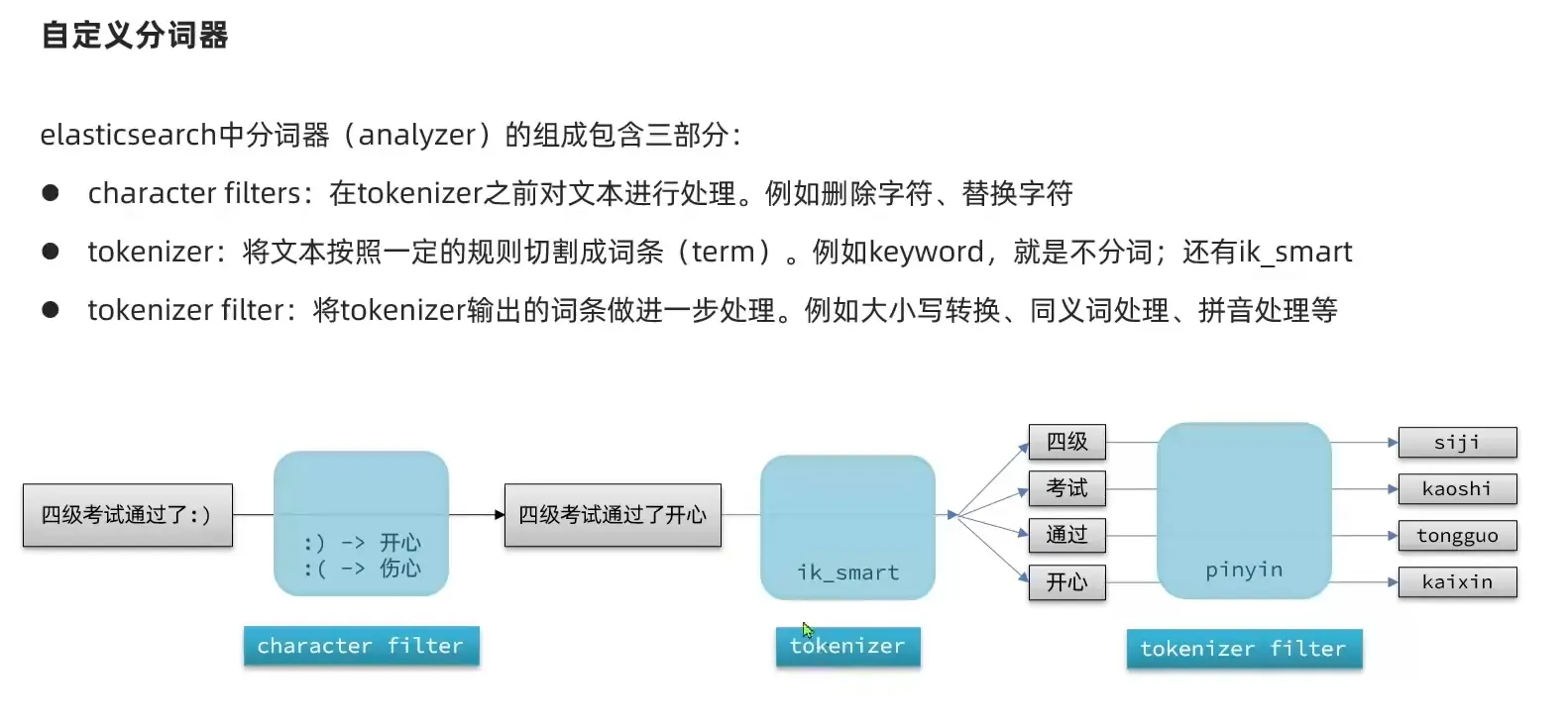
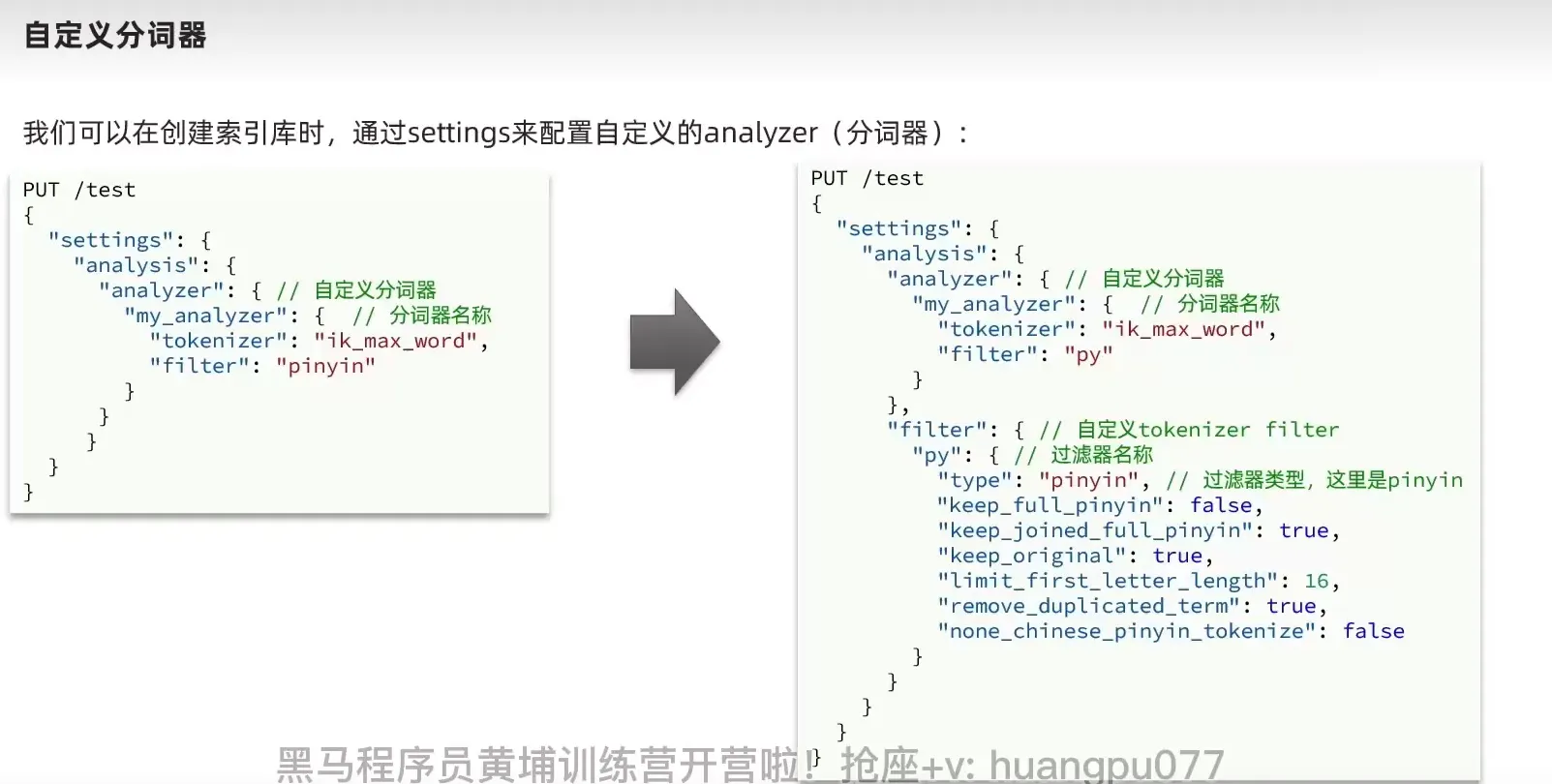
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
|
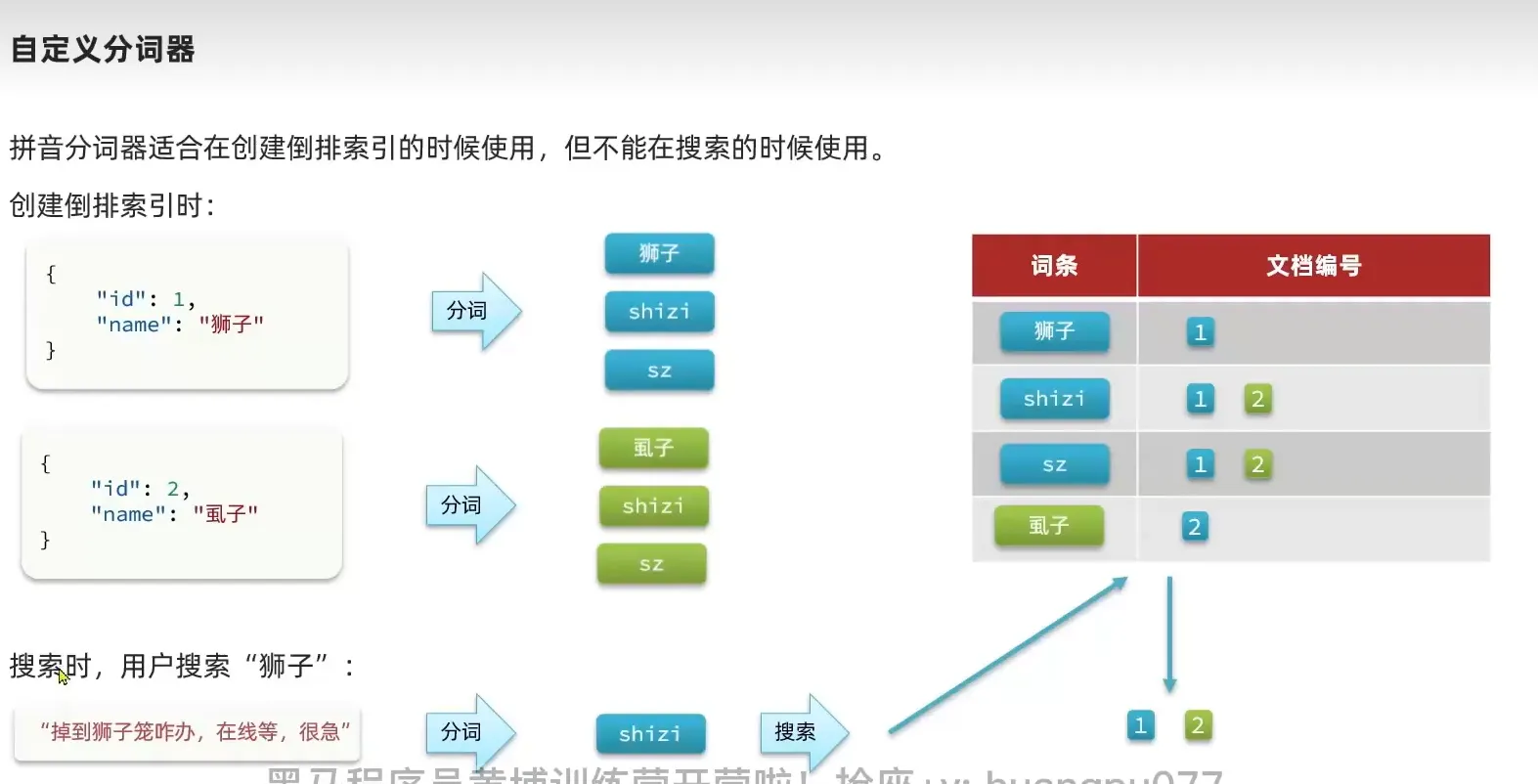
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
|
创建分词器的时候, 使用 拼音分词器, 搜索的时候不要使用
completion suggester查询
1
2
3
4
5
6
7
8
9
10
| PUT test2
{
"mappings" {
"properties": {
"title":{
"type": "completion"
}
}
}
}
|
1
2
3
4
5
6
7
8
9
| POST test2/_doc
{
"title": ["SKii", "ddsfa"]
}
POST test2/_doc
{
"title": ["Sony", "dadsfa"]
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| GET /test2/_search
{
"suggest": {
"titleSuggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}
|
酒店数据自动补全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
|
- 添加一个 Suggestion 类型
- 构造器中添加
1
2
3
4
5
6
7
8
| if(this.business.contains("/")){
String[] arr = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion, arr);
}
else
this.suggestion = Arrays.asList(this.brand, this.business);
|
1
2
3
4
5
6
| GET /hotel/_search
{
"query": {
"match_all": {}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| GET /hotel/_search
{
"suggest":{
"suggestions": {
"text": "h",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
|
‘
RestApi 自动补全
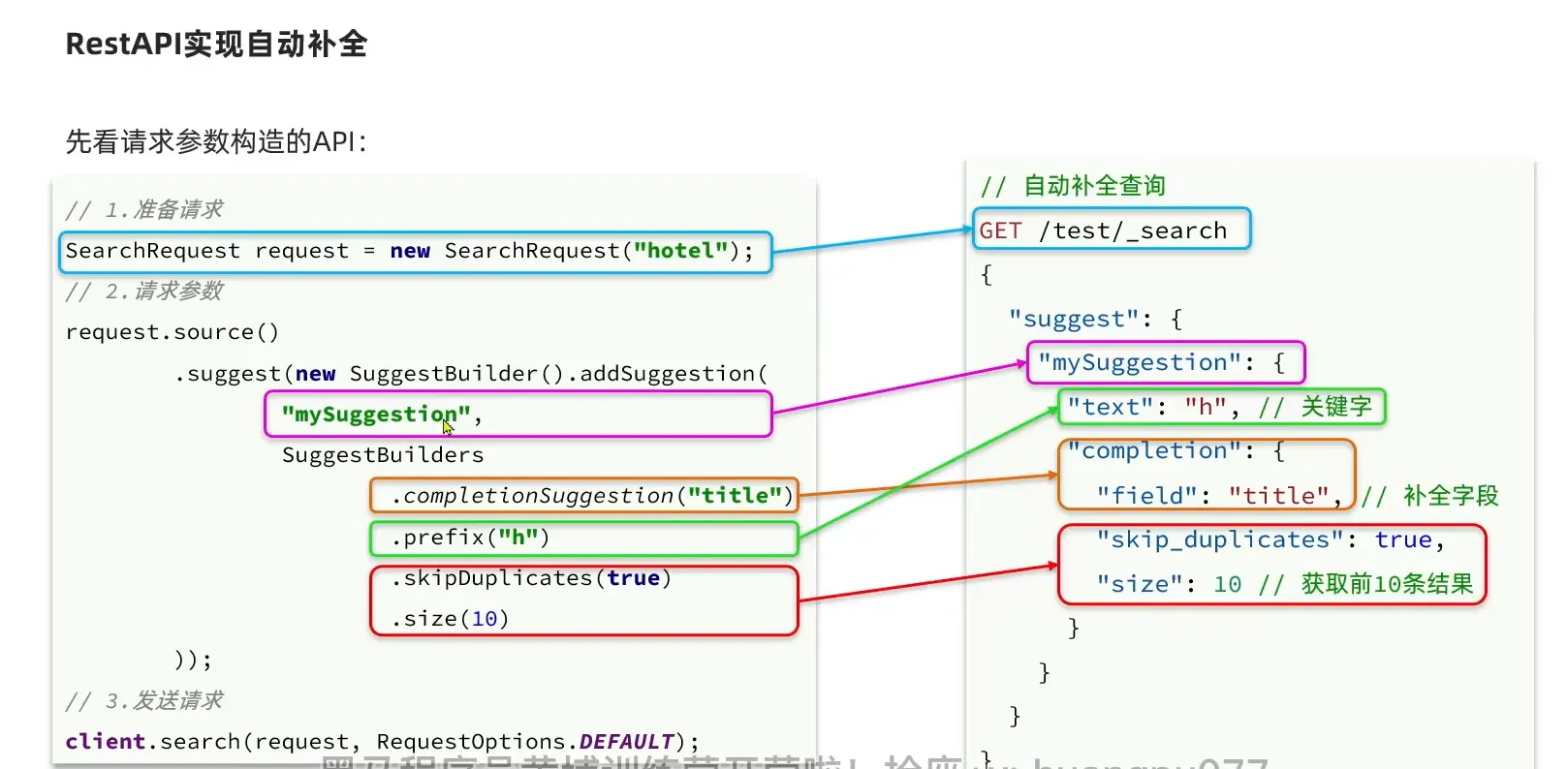
1
2
3
4
5
6
7
8
9
| SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)
));
|

getsuggstion 返回的结果类型等价于 CompletionSuggestion
1
2
3
4
5
6
7
8
9
10
|
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
System.out.println(text);
}
|
数据同步

方案一: 同步调用
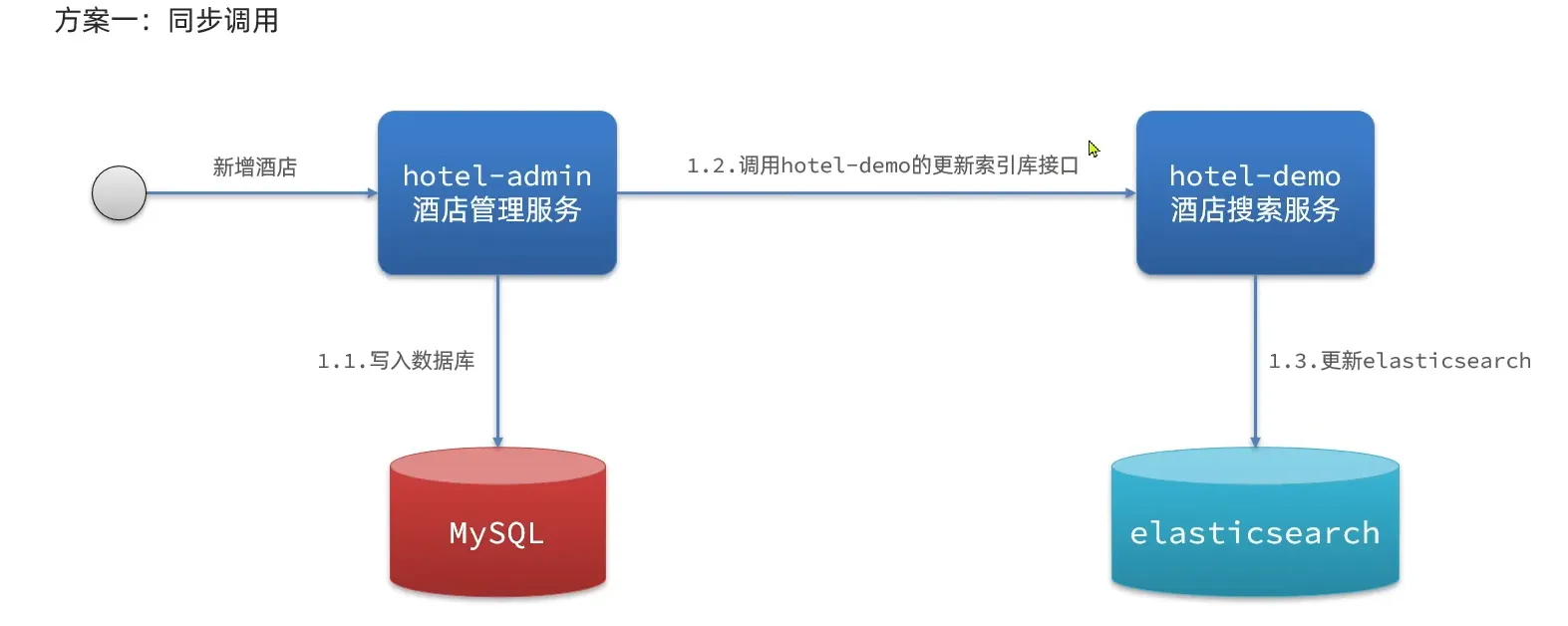
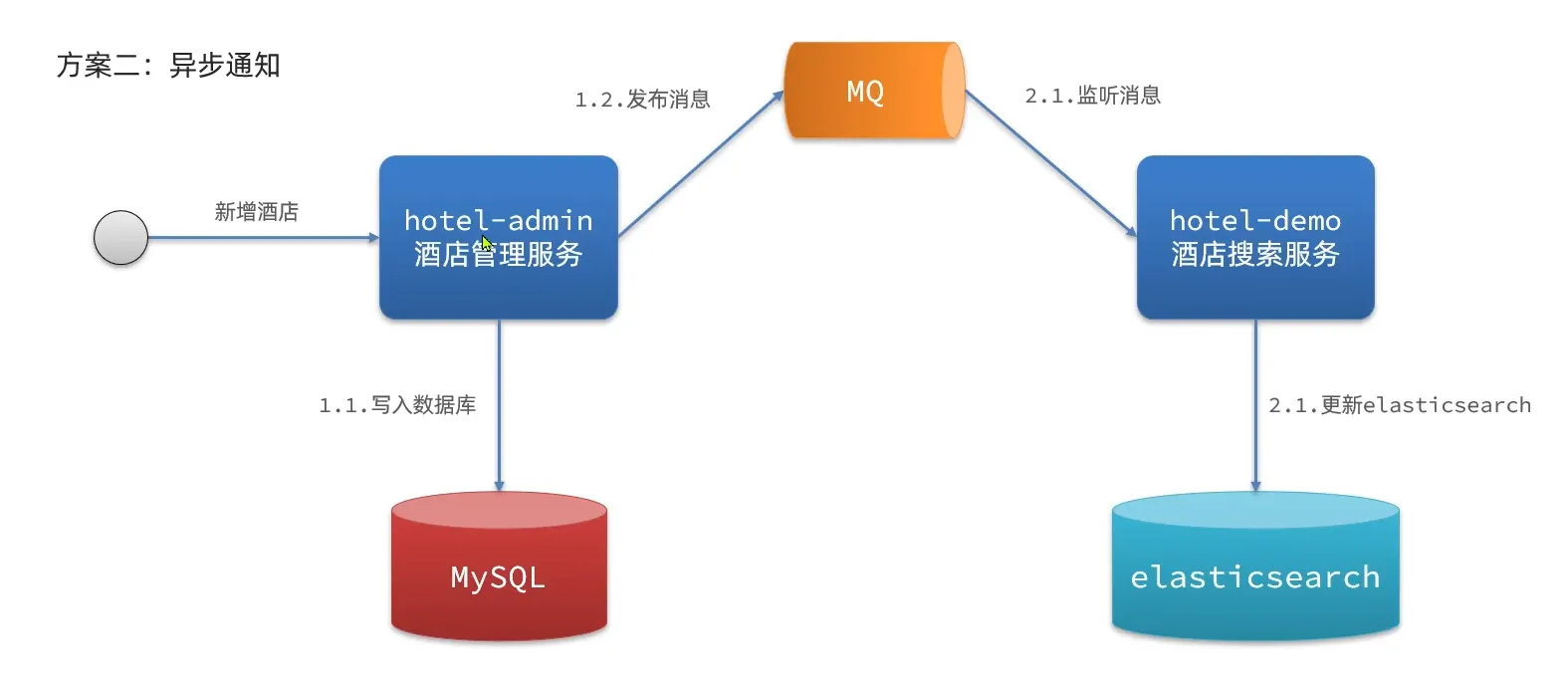
方案二: 异步通知
使用 mq 这个消息队列
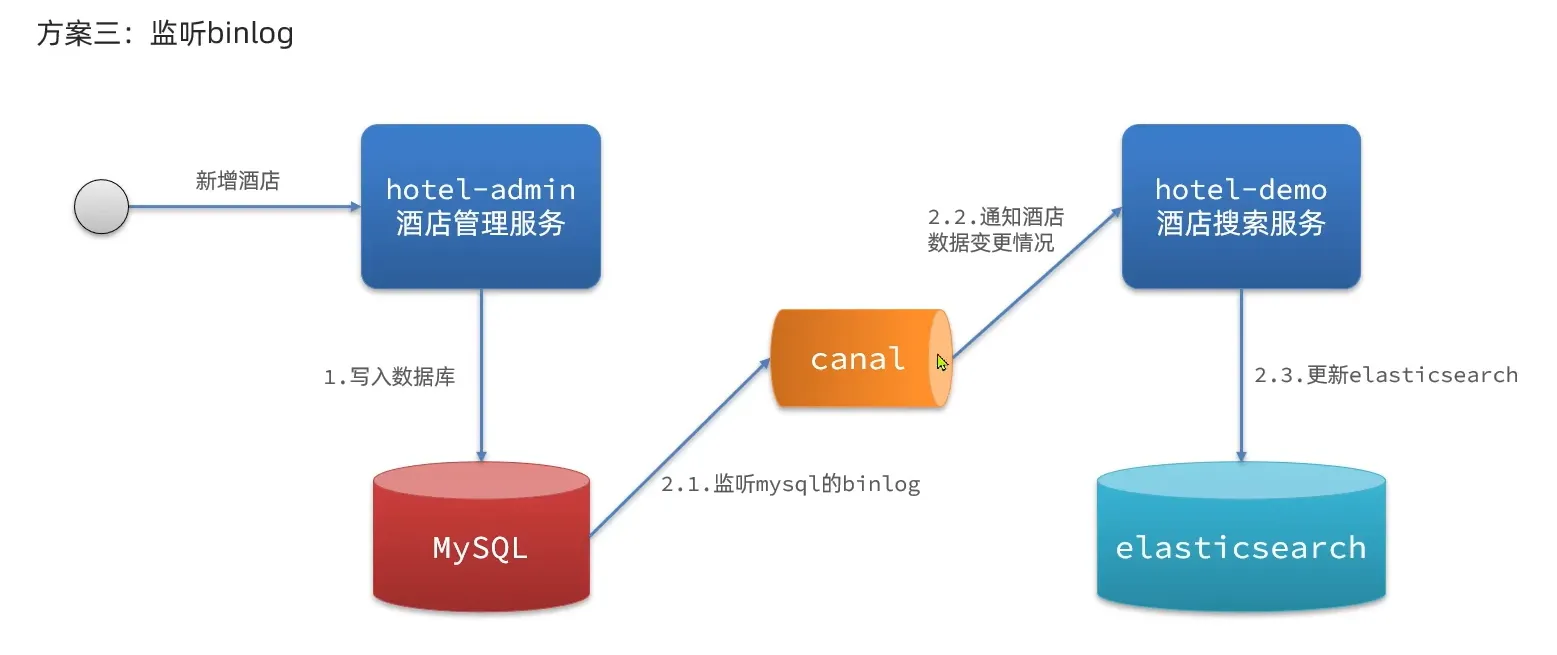
方案三: 监听binlog
使用MQ实现
当酒店发送了增删改的时候, es 也需要增加对应的操作。

在消费者端引入依赖
1
2
3
4
| <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
|
1
2
3
4
5
6
| rabbitmq:
host: 192.168.150.101
port: 5672
username: root
password: wjh114514
virtual-host: /
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class Mqconfig {
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true,false);
}
@Bean
public Queue insertQueue() {
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
@Bean
public Queue deleteQueue() {
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
@Bean
public Binding insertQueueBinding() {
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding() {
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
|
发送消息
1
2
3
4
5
6
| rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_DELETE_KEY, id);
|
监听消息
插入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Override
public void insertById(Long id) {
try {
Hotel hotel = getById(id);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
删除
1
2
3
4
5
6
7
8
9
10
| @Override
public void deleteById(Long id) {
try {
DeleteRequest request = new DeleteRequest("hotel", id.toString());
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
测试修改 和 删除是否可以成功
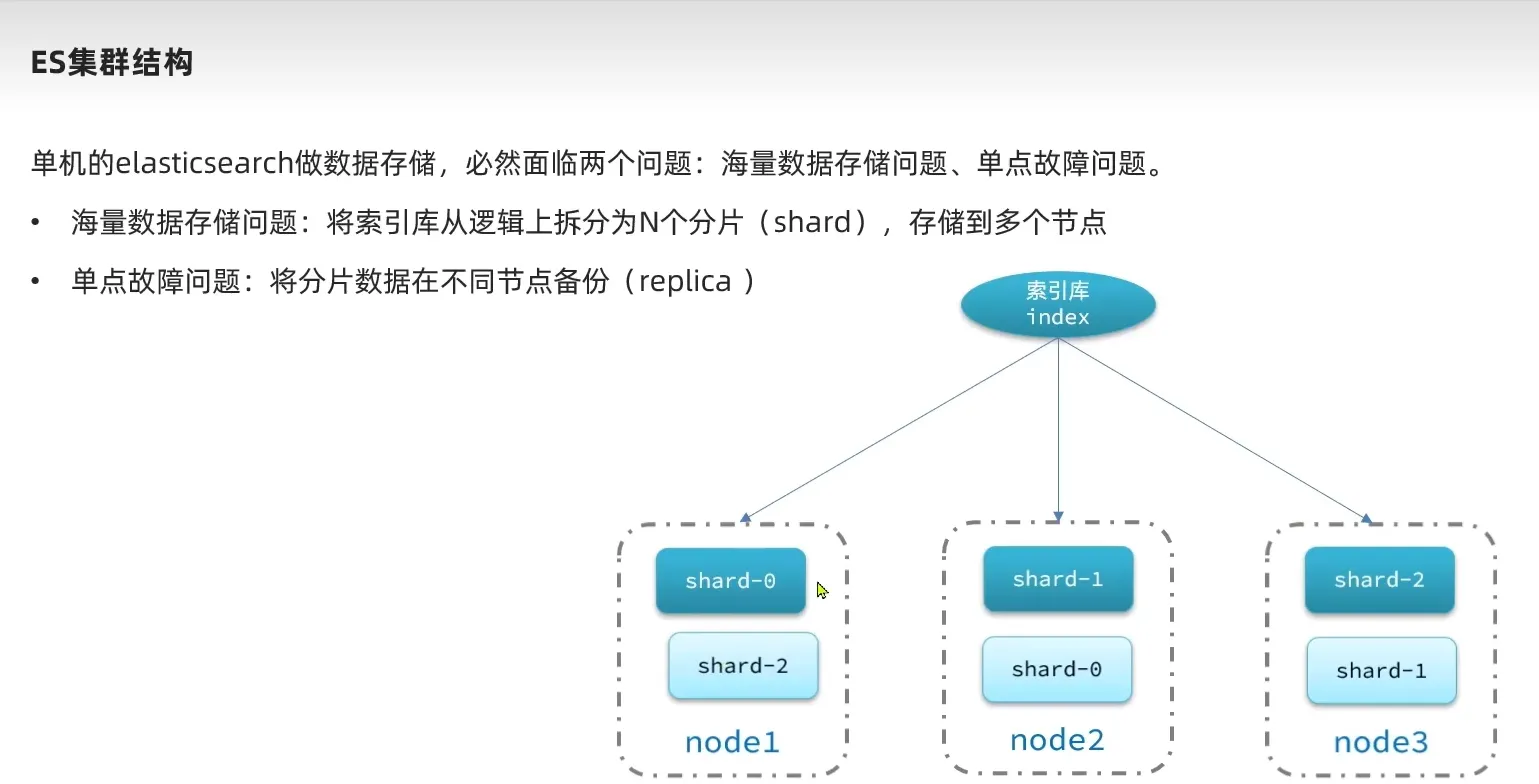
ES 集群
ES 集群搭建