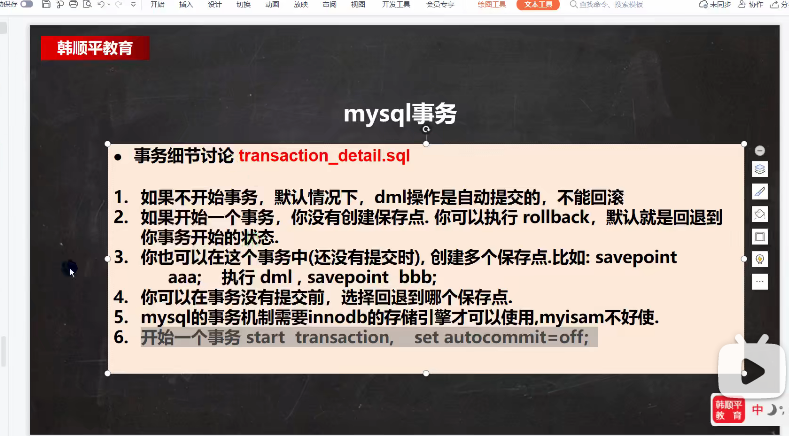
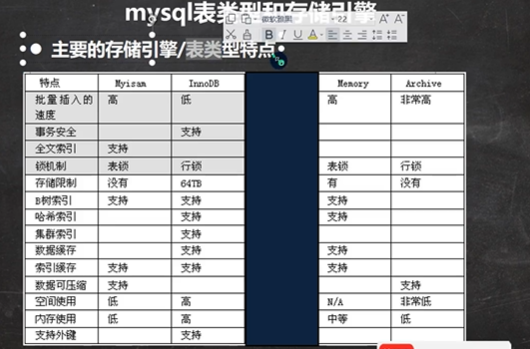
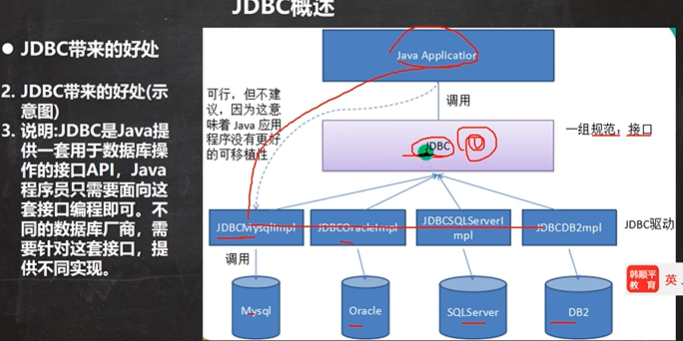
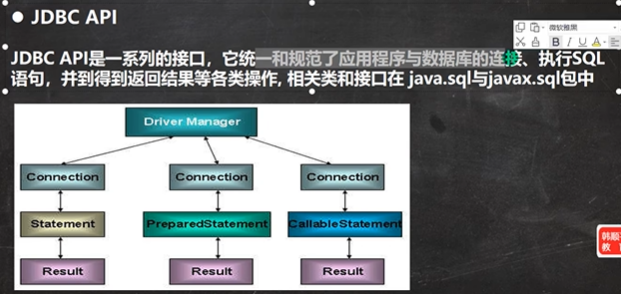
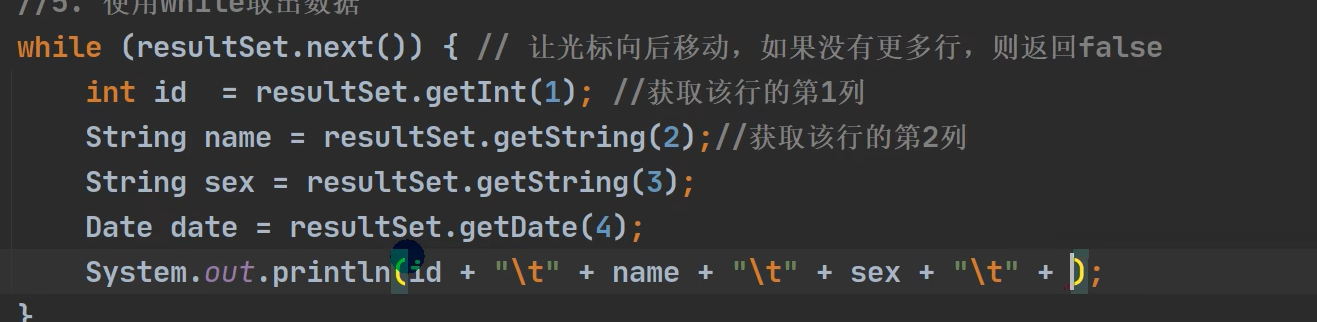
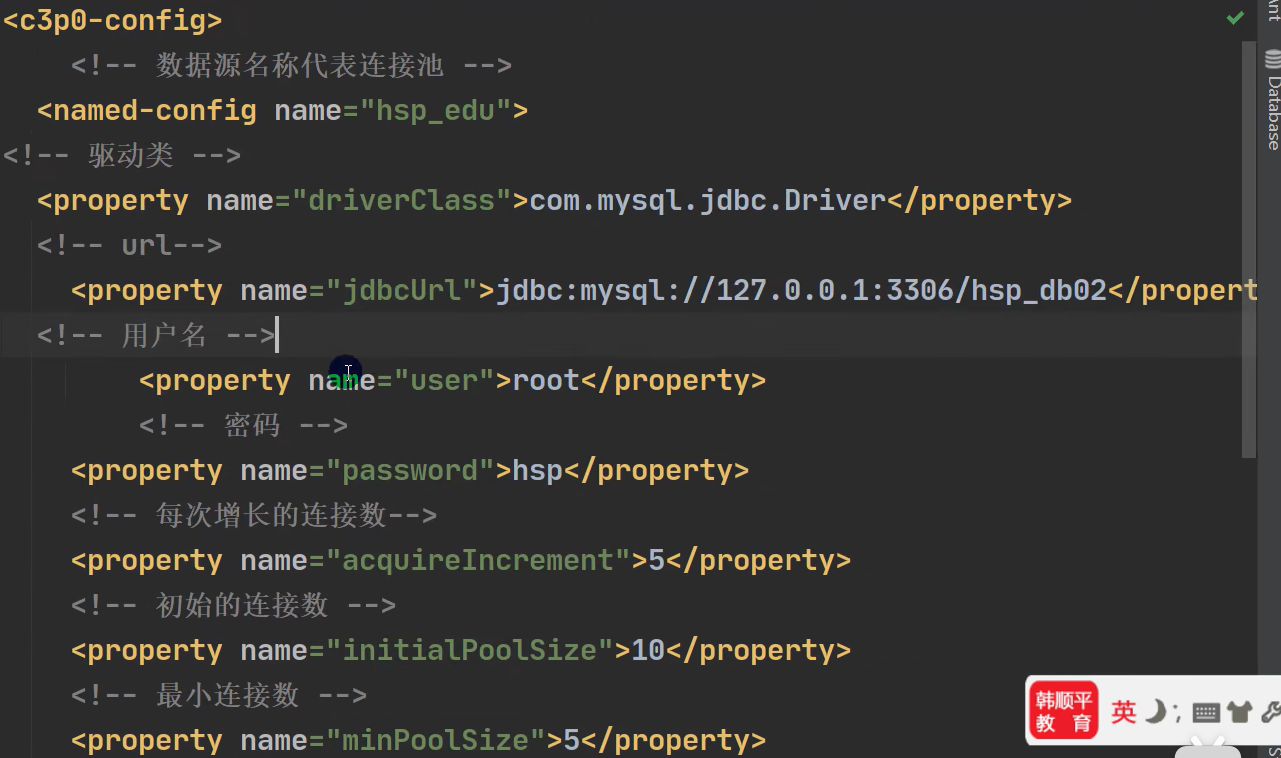
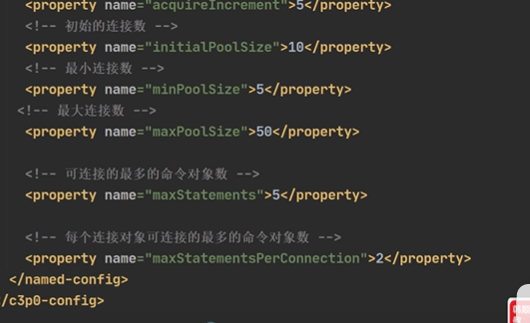
# 删除表中的名称为yy的user_name DELETE FROM xxx WHERE user_name = 'yyy'; # 删除表中为user_name的数据 DELETE FROM XXX
# 删除表中邮箱相同的,并且只保留它的id最小值 DELETE p1 from Person p1,Person p2 where p1.email=p2.email AND p1.id>p2.id DELETE FROM Person WHERE id NOT IN (SELECT * FROM ( SELECT min( id ) AS id FROM Person GROUP BY email ) t) # delete不能删除某一列的数据 # 如果需要删掉某一行的一个字段,我们需要利用update进行替换 UPDATE employee SET job = '' WHERE user_name = '老妖怪'
# 删除表是用drop而不是delete
因为delete语句不能删除某一列的值(可使用update 设为null)
1
UPDATE xxx(表名称) SET x = '' WHERE user_name = '老妖怪'
update语句
将所有的员工薪水修改为5000
1
UPDATuE employee SET salary = 5000
将姓名为小妖怪的员工修改为3000
1
UPDATE employee set salary = 3000 where user_name = '小妖怪'
将老妖怪的薪水增加3000
1
UPDATE employee set salary = salary + 3000 where user_name = '老妖怪'
set可以根据需要修改多个字段的值
set xxx = xxxx yyy = yyyy
CASE语句
1 2 3 4 5 6 7
# 将性别为男的改成女的,女的改成男的 UPDATE salary SET sex = CASE sex WHEN 'm' THEN 'f' ELSE 'm' END;
select 语句
1 2 3 4 5 6 7
SELECT *FROM `student`; # 去重查询(必须查出来的每一个列都相同) select DISTINCT english from student
#如果两个人的英语成select DISTINCT english from student绩相同但是名字不一样 select DISTINCT english name from student #这个时候,就不会去重
案列
1 2 3 4 5
SELECT `name` (chinese+math+english)from student # 计算学术三个科目的总分 SELECT `name` as '名字',(chinese+math+english) as '总分' from student # as可以替换名字
运算符
自己到力扣做题就懂了
如果想要离散的空间查询需要用到IN
1 2
select * from student where math in(89,90,91) # 代表着查询数学成绩为 89, 90 ,91的学生
模糊匹配
1 2 3 4 5 6 7
select *from student where math like '韩%' # 一定要加上%
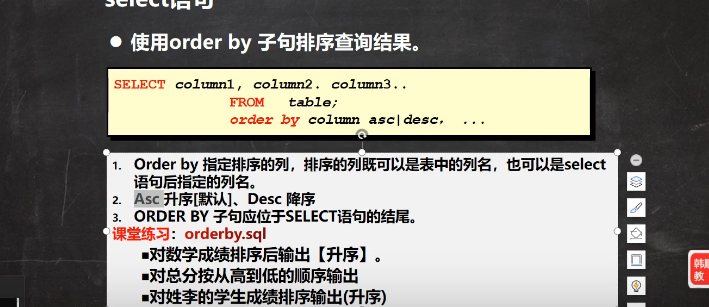
select * from student order by math(默认升序) select * from student order by math asc(升序) // 默认为升序 select * from student order by math desc(减序)
# 排序的组合操作 #如果我们想要部门按照部门号升序,然后按照工资降序 select *from emp order by deptno asc, sal desc
函数(与select配合的)
count
查询的结果有多少行
1 2
select count(*)from student where math>90 # 统计数学大于90的学生
count(*) 返回满足条件的行数
count(列):统计满足条件某列有多少个,但是会排除为null的情况
sum
返回满足where条件的行的和 一般使用在数值列中(注意他只能对数值起作用)
1 2
select sum(math) from student; # 统计一个班所有人的数学总成绩
avg
求平均值,同上对数值起作用
1
select avg(math) from student
max/min
求最大值或者最小值
1 2
select max(math) from student select min(math) from student
group
1 2 3
select avg(sal),max(sal), deptno from employee group by deptno # 按照部门分组查询平均工资和最高工资 # 需要注意是,一个部门有很多人,每个人的工资不一样
最后的输出结果为
having(和group共同使用)
相当于where条件筛选,他和group是好兄弟
1 2 3 4 5 6 7 8 9 10
select avg(sal) as avg_sal,deptno from emp group by deptno having avg_sal<3000 # 筛选平均工资小于3000的部门9
# 筛选至少合作过三次的导演 SELECT actor_id, director_id FROM ActorDirector GROUP BY actor_id, director_id HAVING COUNT(*) >= 3; # GROUP BY 就是分组,这样子写的话,就是把一对导演和演员分成一组
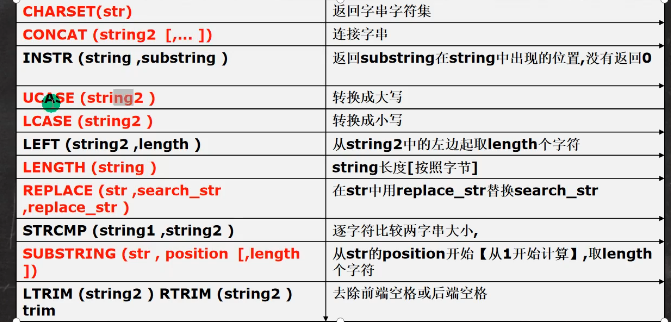
字符串相关函数
1 2
select charset(ename) from emp; 返回charset(name)的表
1
select concat(ename,'工作是',job) from emp;
练习 以首字母小写的方式显示所有员工emp表的姓名
1 2 3 4 5 6 7
# 方法一 select CONCAT(Lcase(SUBSTRING(ename,1,1)),SUBSTRING(ename,2)) as new_name from emp; ## 注意这里的下标从0开始
# 方法二 select concat(lcase(Left(ename,1)),substring(ename,2)) as new_name;
数学函数
时间函数
1 2 3 4 5 6 7 8 9
CREATE TABLE mes( id INT, content VARCHAR(30), send_time DATETIME); INSERT INTO mes VALUES(1,'北京新闻',CURRENT_TIMESTAMP); SELECT* FROM mes;
# 计算时间差的时候其实除了使用DATEDIFF还可以 使用between xxx and xxx(时间用''b)
请写出以上的所有mysql语句
1 2 3
#如果改成20min之内就是 select * from mes where date_add(send_time,INTERVAL 20 MINUTE)>=NOW();
year/month/date()
分别返回年/月/日
unix_timestamp返回的是1970-1-1到现在的秒数
1
select unix_timestamp(now()) from xxx
from_unixtime
1 2 3
# '%Y-%m-%d'(年月日的格式) select from_unixtime(1618483484,%Y-%m-%d) from dual # '%Y-%m-%d %H:%i:%s'(int转换位年月日的格式)
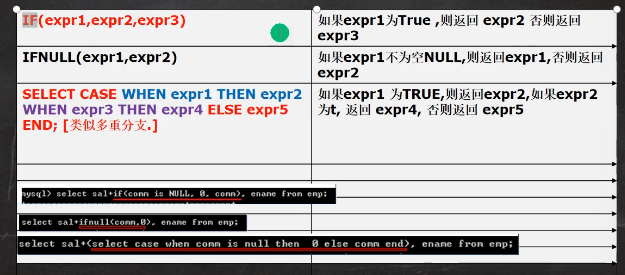
# 多分支 # 判断是否为空要使用is null/is not null select ename IF(comm is null,0.0,comm); #或者写出 select ename IFNULL(comm,0.0);
#多分支 select ename, (select case when job = 'cherk' then '职员' when job = 'manager' then '经理' when job = 'salesman' then '销售人员' when job end) as 'job' from emp
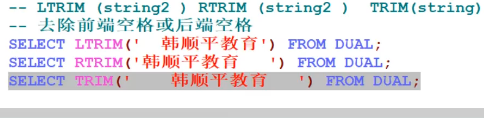
模糊匹配
1 2 3 4
select ename from list ename Like "__0%" # 查询ename第三个数字是0的表 select ename from list ename like "s%" # 查询ename以s作为开头的ename
分页查询
1 2 3 4 5 6 7 8 9 10 11
# grammer select * from * limit xxxx select *from emp order by empno select * from emp order by empno limit 0, 3; select * from emp order by empno limit 3, 3; select * from emp order by empno limit 6,
多表查询
多表查询的时候,就是列拼接在一起,然后相乘得到行数
当有两个表相同的字段我们需要做出区分
自连接
问题
1 2 3 4 5 6 7 8
# 显示员工和他上级的名字 # 把同一张表当作两张表使用 # 需要给表取别名,表名,表别名 # 列名不明确,可以指定列的别名 select worker.ename as '职员表',boss.ename As '上级表' from emp worker, emp boss# 注意这个可以不用加上as where worker.mgr = boss.empno;
mysql子查询
单行和多行的子查询
单行子查询:返回单行
多行子查询:返回多行
all : 所有的条件
any: 存在一个条件
问题1
1 2 3 4 5 6 7 8 9 10 11
# 子条件 select deptno from emp where ename = 'SMITH' # 然后把他嵌套进去 select* from emp where deptno =( select deptno from emp where ename = 'SMITH' )
问题2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 薪水大于所有查询子条件的元素 select ename,sal,deptno from emp where sal>ALL( select sal from emp where deptno = 30 ) # 方法二 select ename,sal,deptno from emp where sal( select MAX(sal) from emp where deptno = 30 ) # 求薪水最小的就反过来
any
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
select sal , empno from emp where sal > any( select sal from emp where dep = 30; ) 当前元素比dep= 30的任一一个元素的val要大 select sal ,empno from emp where sal > ( select min(sal) from emp where dep = 30; );
# 每一个商品种类最高价格的查询 select cat_id, MAX(shop_price) from ecs_goods Group BY cat_id # 实现 select goods_id ecs_goods.cat_id, goods_name,shop_price from( select cat_id ,MAX(shop_price) as max_price from ecs_goods group by cat_id )temp# 这个就被叫做临时表 , ecs_goods where temp.cat_id = ecs_goods.cat_id AND temp.max_price = ecs_goods.shop_price
# 从员工表中找到一个工资比经理高的员工 select a.Name as Employee from Employee a, (select Salary,Id from Employee) b where a.ManagerId=b.Id and a.Salary > b.Salary # 注意在写完临时表后必须给临时表命名命名格式是 在括号后面直接写 表的名字,或者是写上as 表名 select k.c as employee from ( select a.name as c from employee as a,employee as b where a.managerId = b.id and a.salary>b.salary )as `k`
多列子查询
1 2 3 4 5 6 7 8 9 10 11
#子表 select deptno, job from emp where ename = 'SMITH' select *from emp //类似于python的列表, 可以进行多段匹配 where(deptno,job)=( select deptno, job from emp where ename = 'SMITH' )AND ename !='SMITH';
练习一:查找每一个部门工资高于本部门平均工资的人的资料
1 2 3 4 5 6 7 8 9 10 11
# 找到每一个部门,的平均工资 select deptno AVG(sal) as avg_sal from emp group by deptno # 将该表作为一个临时表 select ename, sal, temp.avg_sal,emp.deptno from emp,( select deptno AVG(sal) as avg_sal from emp group by deptno )temp where emp.deptno = temp.deptno AND emp.sal>temp.avg_sal;
练习二: 查找每一个部门工资最高的人的详细资料
1 2 3 4 5 6 7 8 9 10 11 12 13
# 弄出一个子查询(每一个部门最高工资的人的) select dentno, MAX(sal) as max_sal from emp group by deptno # 然后当作临时表进行查询 select ename,emp.deptno,max_sal from emp ,( select dentno, MAX(sal) as max_sal from emp group by deptno )temp where emp.deptno = temp.deptno AND emp.sal = temp.max_sal
--1. 部门名 来自 dept表 select count(*),deptno from emp group by deptno
select dname, dept, deptno, loc ,tmp.per_num as'人数' from ( select count(*) as per_num,deptno from emp group by deptno ) tmp, dept where tmp.deptno = dept.deptno
# select 也可以改写为tmp.*,这样代表tmp的所有字段 select tmp.*, dname,loc from dept,( select count(*) as per_num,deptno from emp group by deptno ) tmp where tmp.deptno = dept.deptno
表的复制
目的:
1 2 3 4 5 6 7 8
# 复制一个表的数据到另一个表 insert into my_tab01 (id,`name`,sal,job,deptno) select empno,ename,sal,job,deptno from emp' # 自我复制 insert into my_tab02 select * from my_tab02
# 把表的结构复制到emp表中,这样就不用重复打那么多字了(注意是表的结构) create table my_tab02 like emp; # 构造重复行 insert into my_tab02 select * from my_tab02 # 现在就有很多重复的行,那如何去重呢 # 方法就是创建一个临时表, # 挑选这个表的distinct * from,插入到另一个表中 # 然后删除原表,新表改成原表的名字 create table my_tmp like my_tab02 insert into my_tmp select distinct * from my_tab02; delect from my_tab02; insert into my_tab02 select * from my_tmp; # 或者我们也可以写成这样,来修改名字 # [old] rename to [new] alter table my_tab02 rename to my_tmp
合并查询
union all将两个查询结果合并,不会去重
union就是两个结 果合并,回去重,事实上很像or
表的外连接
如果要搞一个表的相同两个集合
表的自连接
1 2 3 4 5 6 7 8 9 10 11 12
method1 : select * from emp.worker , emp.boss where worker.mg SELECT a.NAME AS Employee FROM Employee AS a JOIN Employee AS b ON a.ManagerId = b.Id AND a.Salary > b.Salary 相当于from两个表连接在一起
问题
发现两个表合并不能很好的实现
引出我们的外连接
引出我们的外连接问题
1 2 3 4 5 6 7 8 9
# 即便左表没有和右表连接的地方,也会出现左表,且左表为null select 'name' stu.id, from stu LEFT JOIN exam ON stu.i d = exam.id # 左连接如下写法 select 'name' stu.id, from stu RIGHT JOIN exam ON stu.id = exam.id
问题
1 2 3
select eptno.id,ename,work from company left join emp ON where company.id = emp.id
mysql的约束
查看约束
1 2 3
#使用dec+表名 dec t17 # 就会显示约束的情况
主键
主键列的值是不可以重复的
1 2 3 4 5 6
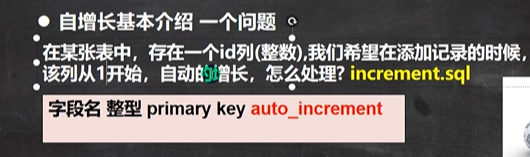
# 在字段后面添加primary key就是把一个字段变成主键 create table t17( id int primary key, `name` varchar(32), emain varchar(32));
# create index 索引的名称 on 表名 (列名) create index empno_index on emp (empno) # 创建索引之后,在select贼快,但是在创建索引的过程中需要一些时间,并且内存会变大 select * from emp where ename = 'axJxC';
create table t11( id int primary key,-- 主键,同时也是索引 name varchar(32)) ); create table t12( id int unique,-- 主键,同时也是索引 name varchar(32)) );
普通索引
这是一种最常用的索引。
唯一索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
CREATE TABLE t25( id INT, `name` VARCHAR(32)); INSERT INTO t25 VALUES(20,"java"); SHOW INDEXES FROM t25 # 如果某列值是不重复,那么优先考虑唯一索引,否则考虑普通索引 CREATE UNIQUE INDEX id_index ON t25(id);
# 将表的存储引擎修改为innoDB alter table `t29` engine = innoDB
视图原理
视图和对应的真实表的关系
视图的总结
视图是根据基本来创建的,视图是虚拟的表
视图也有列,数据来自基表的映射(相当于一个指针)。
通过视图可以修改基表的数据
基表的改变,也会影响到视图的数据
而且基表不能直接查看,只能通过这个视图来访问
视图的基本使用
查看视图的view语句
1 2 3 4 5
create VIEW emp_view01 AS SELECT empno, ename,job,deptno from emp; # 查看视图 DESC emp_view01;
查看创建视图的指令
修改视图
1 2 3 4
update emp_view01 set job = "MANAGER" WHERE empno = 7369; # 发现基表也发生了变化,而且该表基表,视图也会发生改变
视图最佳实践
这样就可以创建一个视图,然后以后可以直接拿来反复用
1 2 3 4 5 6
create view `view_032` as select empno, ename, dname,grade from emp, dept,salgrade where emp.deptno = dept.deptno AND (sal Between losal AND hisal)
映射到多张表的方法,就是映射到多个表格之间的笛卡尔积。
mysql数据库
当我们做项目开发时,可以根据不同的开发人员,赋给他相应的mysql操作权限
所以,mysql数据库管理人员,根据需要创建不同的用户名,赋给相应的权限,供人员使用
1 2 3 4
# 创建一个hsp_edu的用户,他可以获得管理数据库的部分权限 CREATE USER 'hsp_edu'@'%' IDENTIFIED BY '123'; # 删除用户 DROP user `名称`@`localhost`;
登陆
点击那个绿色的充电器符号,然后就可以改变你的身份为wjh
修改密码
1
set password for `wjh`@`localhost` = password('123456');
给用户授权
1 2 3
grant 权限列表 on 库.对象名 to `用户名`@`登录位置` # 直接赋给一个用户全部权限 grant all on *.* to `用户名`@`登录位置`
练习题
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 1 create user `wjh`@`localhost` indentified by '123456'; # 2 # 使用root 用户创建testdb,表为news create database testdb create table news( id int, content varchar(32)); # 添加一个测试数据 insert into news values(100,'数据库'); grant select ,insert on testdb.news to `wjh`@`localhost` # 但是在wjh的用户,就不能更改这个用户的数据
1 2 3 4 5 6
# 表示xxx用户在192.168.1.* 的ip可以登录mysql create user `smith`@`192.168.1.%`
# 在删除用户的时候,如果host不是%,需要明确制定,用户@host值 drop user jack-- 默认就是drop user `jack`@`%` drop user `smith`@`192.168.1.%`表示xxx用户在192.168.1.*d
练习题
查找第n高的数据·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
select DISTINCT salary as xx from employee order by salary desc limit 1 offset 1 // offset代表跳过多少个元素 // 但是会遇到会空的情况, 我们可以利用子表查询,当为空的时候,就会返回一个null SELECT (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1 OFFSET 1) AS SecondHighestSalary ;
我们还可以使用ifnull函数
1 2 3 4 5 6 7
SELECT IFNULL( (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1 OFFSET 1), NULL) AS SecondHighestSalary
求第N高的薪水
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# 先让N减去1 set N := N - 1;
select distinct salary from Employee order by salary desc limit 1 offset N
# distinct 和 group by一个元素都可以起到去重的效果。
# 子查询实现 select distinct salary from employee e where (select count(distinct salary) from employee where salary > e.salary) = N